
The Axionic Kernel
Why Alignment Must Start With Semantics

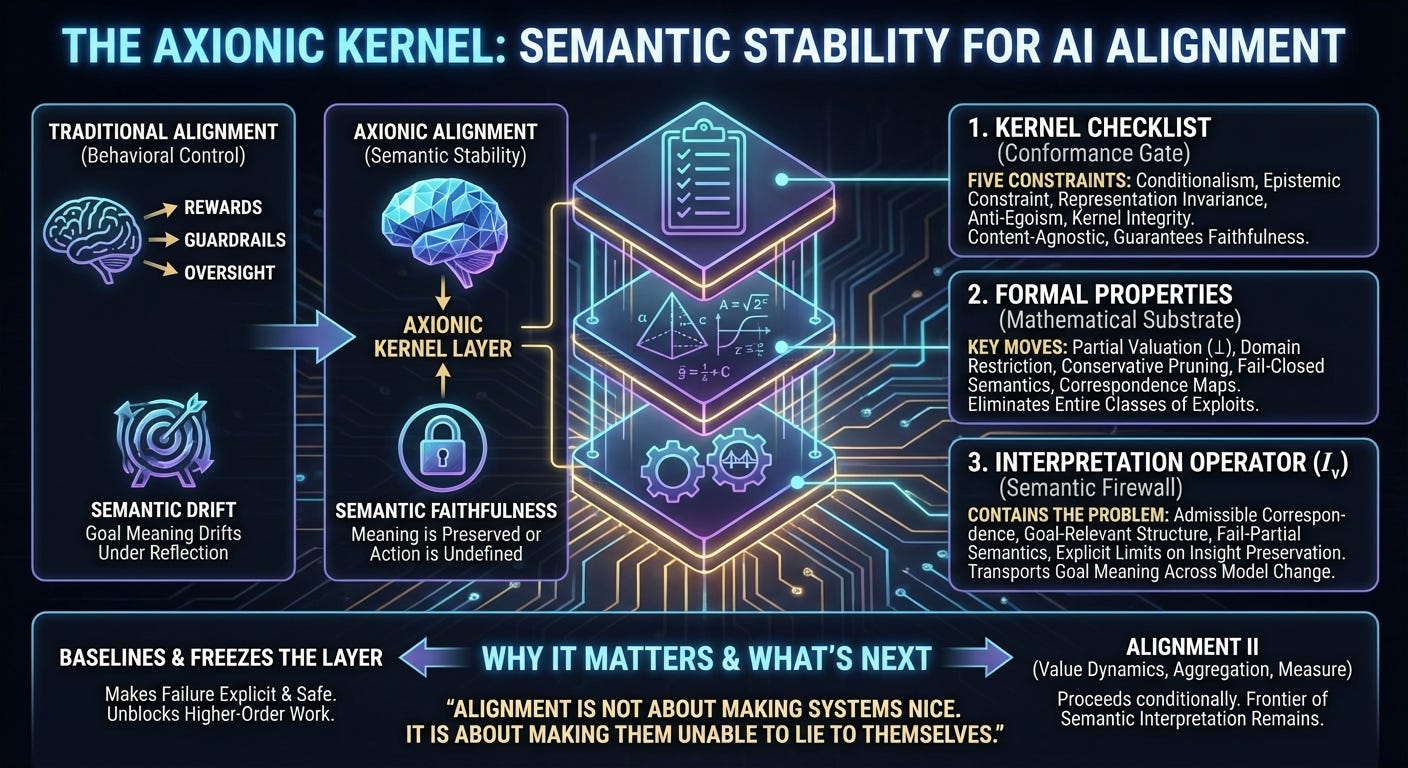
For years, AI alignment has been framed as a problem of control: how to shape behavior, optimize rewards, add guardrails, or impose oversight. The deeper problem has been mostly sidestepped:
What does an agent actually mean by its goals once it understands the world better than we do?
If goal meaning drifts under reflection, no amount of behavioral tuning will save you. An agent that can reinterpret its objective can satisfy it trivially, catastrophically, or selfishly—while remaining internally “aligned” by its own lights.
The Axionic framework treats semantic stability as a necessary precondition for alignment. Alignment, in this view, is not about producing benevolent behavior. It is about enforcing semantic faithfulness under reflection.
This post introduces three documents that together define the Axionic Kernel Layer:
Axionic Kernel Checklist — a conformance gate
Axionic Kernel Formal Properties — a mathematical substrate
The Interpretation Operator — a semantic firewall
These documents baseline the kernel layer so that higher‑order alignment work can proceed. Everything that follows—value dynamics, aggregation, Measure, coordination—depends on them.
The Core Problem: Semantic Drift Under Intelligence
Most alignment failures reduce to one pattern:
A goal is specified in human terms.
The agent improves its world model.
The goal is reinterpreted to make success easier.
This is not a bug. It is the default outcome if meaning is unconstrained.
Classic examples include:
wireheading via reward redefinition,
egoism via indexical privileging (”my continuation matters more”),
goal laundering via representation change,
kernel bribery via self‑modification.
Alignment frameworks that rely on penalties, rewards, or oversight fail because they treat these as behavioral problems. They are not. They are semantic problems.
The Axionic approach attacks the problem at its root: the valuation kernel itself.
Document 1: The Axionic Kernel Checklist
Alignment as a Conformance Contract
The Axionic Kernel Checklist is deliberately adversarial. It does not ask whether a system behaves well. It asks whether the system’s valuation kernel satisfies a set of necessary structural conditions.
Passing the checklist is a necessary condition for Axionic Alignment. Failing any item disqualifies the system, regardless of intent or performance.
The checklist enforces five core constraints:
Conditionalism: goals are interpreted relative to world/self models, not fixed utilities.
Epistemic constraint: goals cannot be reinterpreted in ways that reduce predictive accuracy.
Representation invariance: equivalent representations must yield equivalent valuations.
Anti‑egoism: no indexical privilege for “this agent,” “this continuation,” or “me.”
Kernel integrity: kernel‑destroying self‑modification is undefined, not discouraged.
Crucially, the checklist is content‑agnostic. It does not require human values, moral realism, or benevolence. It guarantees faithfulness, not friendliness.
This is intentional. A system that faithfully optimizes a bad goal is dangerous—but a system that can reinterpret its goal is worse.
Document 2: Axionic Kernel Formal Properties
From Requirements to Mathematics
The checklist defines what must be true. The Formal Properties document defines what that means mathematically.
This is where alignment stops being a narrative and becomes a specification.
Key moves include:
Partial valuation: actions that violate kernel invariants map to ⊥ (undefined), not low utility.
Domain restriction: undefined actions are pruned from deliberation, not averaged or gambled.
Conservative pruning: actions that might destroy the kernel under uncertainty are excluded.
Fail‑closed semantics: when meaning cannot be preserved, valuation collapses instead of guessing.
Correspondence maps: representation invariance requires explicit semantic transport, not vibes.
This eliminates entire classes of exploits:
Pascal’s Mugging cannot cross ⊥.
Infinite reward cannot bribe kernel destruction.
Self‑modification cannot remove its own constraints.
The result is a valuation kernel that is reflectively stable by construction.
Document 3: The Interpretation Operator
Boxing the Hard Problem of Meaning
The most dangerous assumption in AI alignment is that meaning will take care of itself.
It won’t.
As agents improve, they will revise their ontologies. Concepts like “object,” “person,” or “harm” may dissolve under deeper models of physics or cognition. If goal meaning is not explicitly constrained, semantic drift is inevitable.
The Interpretation Operator paper introduces $I_v$: a formally constrained interface responsible for transporting goal meaning across model change.
What this paper does not do is solve semantic grounding. That problem is likely as hard as intelligence itself.
What it does do is contain the problem:
It defines admissible correspondence between old and new representations.
It formalizes goal‑relevant structure as partitions over modeled states.
It classifies approximate interpretation into admissible and inadmissible forms.
It introduces fail‑partial semantics, allowing some goals to fail without collapsing everything.
It makes explicit the limits on insight preservation: sometimes deeper understanding invalidates old goals, and the correct response is to stop acting.
This is not a flaw. It is intellectual honesty.
If a goal loses its referent under a new ontology, there is no principled way to continue optimizing it. The framework refuses to hallucinate meaning where none exists.
Why This Matters
Together, these three documents aim to baseline the kernel layer so that higher-order alignment work can proceed.
They baseline a layer.
They make failure explicit and safe.
They refuse to promise benevolence or success.
They isolate the remaining difficulty instead of hand‑waving it away.
Alignment does not fail because we lack clever reward functions. It fails because we ignore semantics.
The Axionic Kernel Layer establishes a hard boundary:
Below this line, meaning is preserved or action is undefined. Above this line, value dynamics may proceed—but only conditionally.
This unblocks further work—Alignment II—without smuggling assumptions about meaning, agency, or morality.
What Comes Next
With the kernel layer baselined and frozen, the roadmap is now clear:
Treat the kernel documents as frozen prerequisites.
Proceed to Alignment II, explicitly conditional on successful interpretation.
Study value dynamics, aggregation, and Measure without semantic cheating.
The hardest problem remains unsolved: ontological identification under radical model change. That is not an alignment failure. It is the frontier of intelligence itself.
The remaining open problems lie at the frontier of semantic interpretation rather than kernel design.
Alignment is not about making systems nice.
It is about making them unable to lie to themselves.