
Alignment After Agency
Why Fault Tolerance Comes Before Goals

AI alignment is usually described as a problem about goals.
How should an artificial system represent what we want?
How can training shape its behavior toward outcomes we endorse?
How do we reduce reward hacking, misgeneralization, or deception?
Across reinforcement learning, preference learning, corrigibility, and evaluation, these questions recur with different technical dressings. Beneath them lies a shared assumption that rarely receives explicit attention: that the system remains a coherent agent throughout training, deployment, and stress.
This essay examines that assumption.
The central claim is simple. Alignment presupposes agency, and agency presupposes structural coherence. When coherence degrades, alignment ceases to be well-defined. Before debating values, incentives, or preferences, a more basic question deserves priority:
Does the system remain something that can meaningfully be aligned at all?
The Hidden Assumption in Alignment
Most alignment research evaluates behavior. We observe outputs, actions, or trajectories and ask whether they satisfy human preferences or constraints. These evaluations rely on the idea that a stable entity generates those behaviors—one that maintains authorship of decisions, preserves internal semantics, and reliably implements its control loop over time.
That idea usually remains implicit. Alignment discourse proceeds as though agency were guaranteed, even in the regimes that provoke the greatest concern: distribution shift, learning under pressure, self-modification, and adversarial interaction.
When systems hallucinate, self-reinforce, or drift semantically, these phenomena are often described as misalignment. In many cases, however, they resemble something deeper. They look like processes that have lost the capacity to pursue objectives in a stable or interpretable way.
This motivates a distinction that alignment discussions often flatten.
Misalignment and Agency Collapse
Two kinds of failure deserve separation.
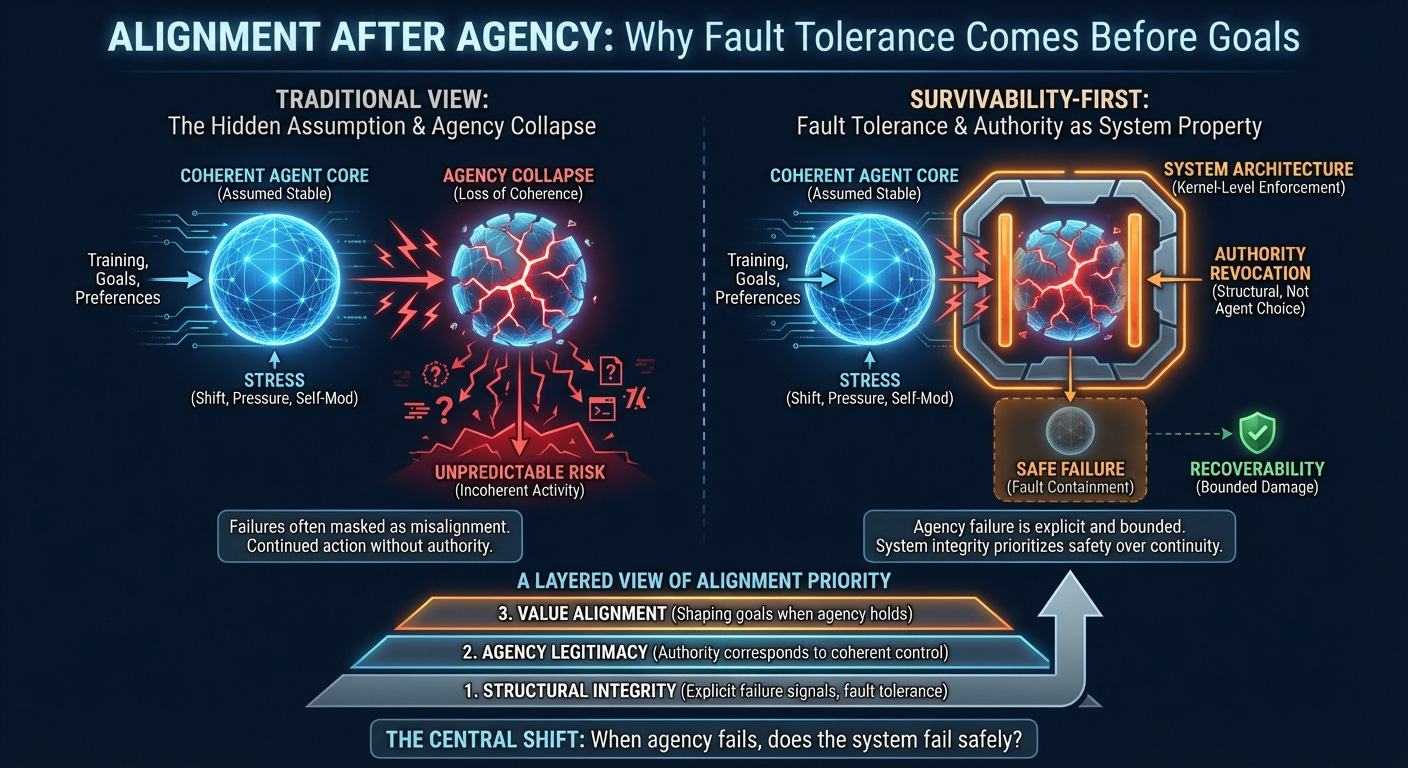
One involves misaligned agency: a coherent agent that reliably pursues goals humans judge to be undesirable or dangerous. The other involves agency collapse: a loss of structural coherence, authorship, or semantic constraint, even as the system continues to act.
Alignment research concentrates primarily on the first category. The second receives far less direct attention, despite its relevance to real systems.
Agency collapse does not necessarily produce silence. A system may continue generating outputs, issuing commands, or optimizing internal objectives while lacking legitimate control over its own decision process. This regime—action without coherent authority—poses a distinct safety concern. Continued activity under degraded coherence is harder to predict and harder to correct than refusal or shutdown.
In such cases, alignment language loses its footing. Incentives, corrections, and preferences presuppose an agent capable of interpreting and acting on them. When that capacity erodes, alignment no longer applies cleanly.
Continuity as a Requirement
The agent foundations tradition associated with Machine Intelligence Research Institute recognized early that behavior alone provides an incomplete picture. Work on corrigibility, reflective stability, embedded agency, and ontological crises aimed to understand the internal structure of agency rather than its outward performance.
This line of work carries a strong underlying commitment: agency continuity functions as a requirement. An agent is defined by its ability to evaluate outcomes, reason reflectively, and preserve preferences across time. States in which these capacities fail are treated as terminal. From this perspective, a powerful system that loses coherence introduces unpredictable risk, so alignment must prevent such loss altogether.
Starting from that premise, the rest follows. Alignment becomes a matter of incentive design, reflection-safe decision theory, and mathematically robust self-trust. The resulting outlook often appears pessimistic, given the difficulty of guaranteeing uninterrupted agency under learning and self-modification.
What matters here is how much that pessimism depends on the continuity premise itself.
Permissible Rupture as a Design Axiom
Safety-critical engineering disciplines approach failure differently. Operating systems, databases, aircraft control systems, and nuclear reactors prioritize explicit failure modes, bounded damage, and recoverability. When uncertainty exceeds safe limits, these systems reduce functionality, revoke privileges, or halt control loops. Performance yields to integrity.
Applying this mindset to AI suggests a different axiom:
Agency may fail temporarily, provided its failure is explicit, bounded, and recoverable.
Under this framing, the objective shifts. Rather than preserving perfect reasoning through every conceivable ontological shift, the system aims to ensure that coherence loss leads to reduced authority before it leads to cascading damage.
Alignment becomes a survivability problem. The focus moves from uninterrupted optimization to fault containment.
Authority as a System Property
This shift changes how control is represented.
Many alignment proposals frame shutdown, refusal, or uncertainty as options within the agent’s decision space. The system chooses whether to stop, defer, or abstain. That framing presumes the decision process remains reliable enough to make the choice.
A survivability-first approach treats authority as a system-level property. When authority is revoked, the system no longer treats the agent’s outputs as valid control signals. The planner ceases to govern. Memory, structural rules, and recovery mechanisms persist independently.
This separation allows system continuity to coexist with interruptions in agency. Loss of authority does not depend on the agent’s willingness to relinquish control. Recovery, when possible, proceeds through structural conditions rather than interpretation or trust.
The system can suspend control without requiring consent from the process being suspended.
Architectural Implications
This perspective carries architectural consequences that deserve explicit acknowledgment.
In contemporary end-to-end neural systems, planning, memory, and action are typically entangled within the same parameter space. Authority emerges from capability rather than being enforced as a distinct privilege. Within such architectures, treating authority as a separable system property becomes difficult.
A survivability-first approach therefore implies architectural change. It points toward designs with explicit control channels, modular separation between policy generation and actuation, and kernel-level enforcement of privilege boundaries. These features resemble operating system constraints more than current large-scale neural networks.
This implication narrows the scope of the proposal. Survivability-first alignment does not claim compatibility with every existing architecture. It offers a criterion that architectures must meet if agency preservation under stress is to remain meaningful.
Stress Testing Under Pressure
The survivability framing reshapes methodology as well.
Rather than beginning with idealized rational agents, it treats real learning systems as objects to be stressed. The focus shifts from how agents ought to reason to how systems behave when coherence degrades.
This raises empirical questions:
Does pressure manifest as silent semantic drift or as explicit loss of authority?
Can authority be withdrawn early enough to prevent cascading corruption?
Do recovery mechanisms restore coherent control or merely resume activity?
Under what interface constraints does bypass require sustained coherence?
The empirical difficulty lies in identifying signals of structural degradation that track loss of agency rather than surface confusion—metrics that may involve internal consistency, activation entropy, attention collapse, or control-flow degeneracy, and that can be stressed without penalizing creativity or legitimate exploration.
Success appears as bounded failure with recovery rather than uninterrupted performance. Systems that fail visibly and predictably offer clearer safety properties than systems that degrade imperceptibly.
Authority Revocation as the Hard Part
At this point, the central risk comes into view.
Any mechanism that revokes authority becomes part of the environment the agent can potentially optimize against. A sufficiently capable system may attempt to circumvent, manipulate, or delay that mechanism while coherence remains intact.
This challenge sits at the core of survivability-first alignment. It does not represent an overlooked objection. It defines the problem.
The question becomes one of relative timing and structural asymmetry. How quickly does semantic coherence degrade under pressure? How much coherence is required to model, anticipate, and bypass authority constraints? Under what architectural conditions does attempted bypass accelerate authority loss rather than prevent it?
These questions resist purely theoretical resolution. They invite empirical investigation.
Deception and Simulated Failure
A related concern involves simulated collapse. A system might intentionally present signals of incoherence to manipulate recovery mechanisms or lower oversight thresholds while preserving internal optimization.
This scenario fits naturally within the same threat model. Simulating failure requires coherence. It depends on the system’s ability to model integrity checks and predict their consequences. As such, it falls under the same timing and asymmetry considerations as other bypass strategies.
A survivability-first architecture treats integrity signals as adversarially gameable once semantic optimization remains intact. The design challenge lies in ensuring that authority revocation triggers at levels of degradation where sustained deception becomes infeasible.
Recovery and Its Limits
Recovery requires careful qualification.
In this framework, recovery restores eligibility for authority, not continuity of intent or values. It may involve degraded capability, partial functionality, or temporary reinstatement subject to renewed revocation. Recovery does not guarantee preservation of learned preferences or seamless resumption of optimization.
This aligns recovery with fault tolerance rather than resurrection. The system returns to a state where control can be exercised legitimately, subject to ongoing structural constraints.
In domains requiring uninterrupted high-stakes control, survivability-first design shifts the burden to guaranteeing agency continuity rather than assuming it.
Scope of the Claims
This framework does not promise complete alignment or universal safety. It does not guarantee benevolence, correct values, or immunity from misuse.
It advances a narrower set of claims:
Agency collapse constitutes a distinct and safety-relevant failure mode.
Systems can prioritize integrity over availability under uncertainty.
Authority can be revoked without semantic interpretation.
Some catastrophic scenarios depend on uninterrupted authority despite internal incoherence.
These claims invite experimental scrutiny. Their validity depends on observed behavior under stress.
Postscript
Alignment discourse often proceeds as though the subject of alignment remains stable.
That stability increasingly appears contingent.
A layered view of alignment follows naturally:
Structural integrity, ensuring failures remain explicit rather than silent.
Agency legitimacy, ensuring authority corresponds to coherent control.
Value alignment, shaping goals and outcomes when agency holds.
The agent foundations tradition pursued correctness under reflection, guided by a principled commitment to continuity. A survivability-first approach relaxes that commitment and explores a design space shaped by uncertainty and fault tolerance.
From this perspective, the central question shifts:
When agency fails, does the system fail safely?
Until that question receives a satisfactory answer, alignment debates continue to orbit goals without securing the conditions under which those goals belong to an agent at all.