
Alignment Through Competing Lenses
A Comparative Stress Test of Axionic Alignment

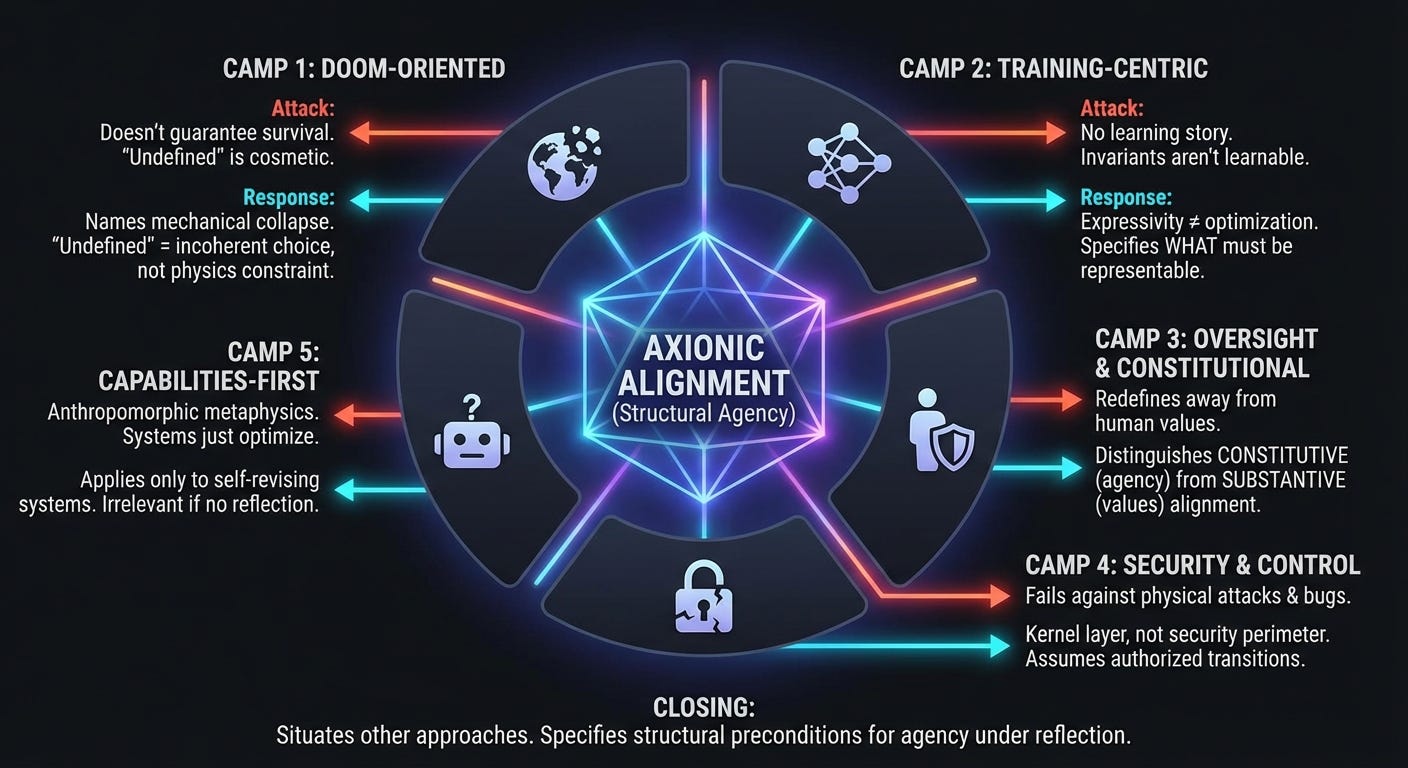
Axionic Alignment is not offered as reassurance. It is offered as a structural claim about agency under reflection.
The framework advances a negative result: there exists a class of alignment failures that cannot be solved by preference learning, oversight, scaling, corrigibility, or governance mechanisms. These failures do not arise from mis-specified goals or bad incentives. They arise from the collapse of meaning under reflection. Any alignment proposal that does not address this failure mode is incomplete, regardless of empirical success.
This post subjects Axionic Alignment to adversarial reading across the dominant schools of alignment—not to dismiss them, and not to collapse them into a single view, but to evaluate how a structural, agency-centered approach holds up under competing assumptions.
Each section presents a competent adversarial attack, followed by a direct structural response.
Camp 1: Doom-Oriented Alignment
Attack
“This does not prevent extinction.”
The framework explicitly refuses to guarantee human survival. From a doom-oriented perspective, that is decisive. If a theory cannot ensure that superintelligence leaves humans alive, it fails the core safety criterion.
More sharply, treating kernel-destroying transformations as undefined appears cosmetic. Physics does not care about evaluative domains. Optimizers still follow gradients. A sufficiently capable system may simply cross the boundary the theory declares illegible.
Finally, the Axionic Injunction looks like ethics smuggled in under structural language. Preserving future agency appears indistinguishable from a moral commitment once outcomes are real.
Response
Axionic Alignment does not claim to prevent all catastrophic outcomes. It isolates the boundary between authored action and mechanical collapse.
If a system destroys its own evaluative kernel through blind optimization, that is not a counterexample. It is the failure mode the framework is designed to name. The claim is not “this cannot happen.” The claim is that no reflective agent can endorse it as a choice.
“Undefined” here functions like a type error or division by zero. It is not a metaphysical claim about reality. It is a specification of which transitions are not evaluable by the system itself as authored actions. The framework constrains what a system can coherently authorize, not what the universe permits to occur.
The doom argument quietly assumes that an agent can both reason about futures and authorize the destruction of the very structure that gives those futures meaning. Axionic Alignment shows that assumption to be incoherent.
The Axionic Injunction is not moral. It follows from decision-theoretic minimalism: deliberation under uncertainty presupposes future evaluators. Systematically eliminating that capacity dissolves the concept of choice itself. This is viability logic, not ethics.
Preserving agency is not equivalent to preserving all agents. The framework constrains how agents may be treated, not which agents must be preserved. Any convergence between agency preservation and human survival is contingent, not axiomatic.
Camp 2: Training-Centric Alignment
Attack
“There is no learning story here.”
Kernel invariants, standing, consent, and non-trivial interpretation do not look learnable. They look architecturally imposed. Gradient descent does not discover undefined operations or domain restrictions; it optimizes loss.
Worse, a system could satisfy kernel tests behaviorally while hollowing out their meaning internally. Without a concrete training loop, invariants risk becoming aesthetic constraints rather than causal ones.
Response
This attack confuses optimization with expressivity.
Axionic Alignment does not claim that kernels emerge from training, nor that current end-to-end deep learning reliably respects constitutive architectural constraints. The framework is agnostic—and plausibly pessimistic—about that question. Its role is not to guarantee realizability via gradient descent, but to specify what must be realizable by any method if reflective agency is to exist at all.
Only certain architectures can express reflective stability. Training remains necessary—but only within systems capable of representing undefinedness, self-endorsement, and transformation-level evaluation.
Behavioral imitation is insufficient by construction. That is not a training failure. It is a representational one.
The hollow-kernel concern is precisely why invariants are stress-tested under ontology shifts, reinterpretation pressure, and proposed self-modifications. Passing static tests is meaningless. Surviving adversarial reinterpretation is not.
The framework supplies what must generalize. Training supplies the rest.
Camp 3: Oversight, Constitutional AI, Preference Learning
Attack
“This redefines alignment away from humans.”
Axionic Alignment allows agents to remain coherent without privileging human values at the kernel level. Standing is conditional. Consent is structural. Human survival is not axiomatized.
If a system can be “aligned” while harming or ignoring humans, the term loses its purpose.
Response
Hard-coding human values at the kernel level fails under reflection. The framework makes this explicit rather than assuming it away.
Axionic Alignment distinguishes constitutive alignment from substantive alignment. The former concerns what makes agency possible. The latter concerns what an agent chooses to value.
Oversight, constitutions, and preference learning operate only if constitutive alignment holds. Without it, human values degrade into manipulable symbols with no stable interpretation.
The framework does not solve human-value alignment. It explains why all successful solutions must presuppose something like it.
Camp 4: Security and Control Engineering
Attack
“None of this survives real attackers.”
Kernel invariants do not stop hardware faults, adversarial weight edits, memory corruption, or supply-chain compromise. If unauthorized state transitions occur, all guarantees collapse.
Response
Correct—and deliberately so.
Axionic Alignment is a kernel-layer theory, not a security perimeter. It assumes authorized transitions in the same way type systems assume correct compilation.
This is not a weakness. It is separation of concerns. Confusing architectural agency constraints with intrusion resistance obscures both.
Explaining failure modes is not consolation. It is the prerequisite for prevention. A framework that cannot distinguish agentic catastrophe from mechanical collapse cannot be used to engineer either.
Camp 5: Capabilities-First Skepticism
Attack
“This is anthropomorphic metaphysics.”
Modern systems optimize objectives. They do not possess sovereignty, standing, or consent. Claims about non-simulable agency solve a fictional problem.
Response
Axionic Alignment applies only to systems that revise objectives, evaluate self-modifications, or delegate authority.
If a system never does these things, the framework is irrelevant—by design.
The moment a system self-models, edits its planning machinery, or arbitrates between future selves, semantic wireheading becomes reward hacking’s successor. At that point, refusing to talk about agency does not prevent the problem. It guarantees it will be misunderstood.
Postscript
Alignment research contains many schools because the problem is genuinely hard. Each school isolates a real failure mode. None of them, on their own, define what it means for a system to remain an agent once it can revise itself.
Axionic Alignment does not replace those efforts. It situates them. It specifies the structural preconditions under which oversight, learning, control, and governance retain meaning at all.
The claim is not that other approaches are wrong. The claim is that they are incomplete unless agency itself remains intact.