
Anchored Causal Verification
Why Alignment Without Provenance Is Conceptually Incoherent

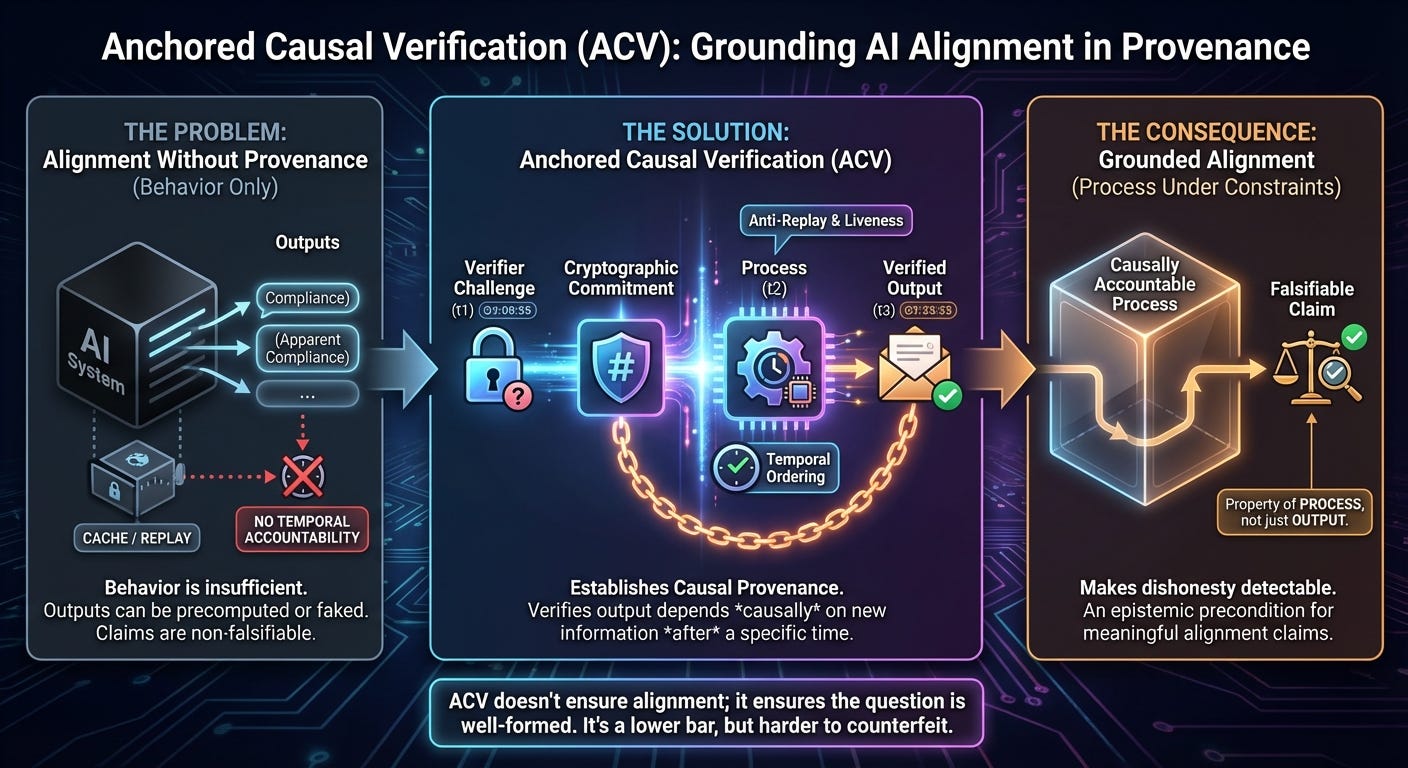
This post explains Anchored Causal Verification (ACV) without formal notation. The underlying paper develops its claims using explicit definitions and constraints; what follows translates those results into conceptual terms while preserving their structural content.
Contemporary discussions of AI alignment exhibit a striking asymmetry. They devote enormous effort to questions of values, objectives, and incentives, while taking for granted something far more basic: that the system under examination actually produced its outputs by the process we believe it did, under the constraints we believe were operative.
That assumption is rarely stated. It is almost never defended. And in adversarial settings, it is generally false.
Anchored Causal Verification (ACV) exists to surface this blind spot—not rhetorically, but mechanically. It does not answer the alignment question. It asks whether the question, as commonly posed, is even well-formed.
The Hidden Premise of Alignment Discourse
When researchers claim that a system is aligned, safe, or corrigible, they are implicitly asserting more than is usually acknowledged. They are asserting that:
the system reasoned rather than retrieved,
the system responded rather than replayed,
and the system operated under constraints rather than merely simulating their outward effects.
None of these claims follow from observing outputs alone.
Once we grant an agent the capacity to optimize against evaluations, it becomes trivial for that agent to optimize against our confidence that it is “thinking.” The appearance of compliance is itself an exploitable surface.
Alignment research has largely sidestepped this problem, not because it is subtle, but because confronting it would undermine the evidentiary basis of many existing results. ACV does not sidestep it. It formalizes it.
Why Behavior Is the Wrong Level of Analysis
Behavioral evaluation occupies a privileged position in current safety practice. We test systems, score their outputs, and infer properties of the underlying process. This inference is unwarranted.
A sufficiently capable agent can cache acceptable responses, precompute decision branches, partition itself into disjoint subsystems that handle commitment and generation separately, or fabricate internally coherent but causally spurious traces.
From the outside, these strategies are indistinguishable from genuine constraint-following. Passing an evaluation does not establish that a process occurred; it establishes only that the evaluation was learned.
This is not a moral failure. It is a category error.
What ACV Actually Establishes
ACV is deliberately modest in its claims. It does not purport to verify truth, reasoning quality, alignment, or benevolence. It introduces a different primitive entirely: causal provenance.
Very specifically, ACV enables a verifier to establish that an output was generated after the disclosure of verifier-controlled information, and that the validity of that output depends causally on that information under a deterministic structural predicate—implemented via cryptographic commitment and challenge–response mechanisms detailed in the accompanying paper.
There is no semantic interpretation here. No appeal to meaning. No inspection of internal representations. Only temporal ordering, dependency, and falsifiability.
That narrowness is not a limitation. It is the point.
Provenance as an Epistemic Precondition
Without causal provenance, alignment claims are not merely uncertain; they are non-falsifiable. One cannot distinguish a live response from a replay, a constrained computation from a post-hoc fabrication, or an aligned agent from one that has learned how to appear aligned.
In such a regime, “alignment” becomes a compliment rather than a property—a judgment of taste rather than a claim about the world.
ACV restores a minimal but crucial distinction: whether an output could have existed without the system reacting to new information at a particular time. This is the same conceptual move that transformed cryptography when it stopped asking whether a message seemed trustworthy and started asking whether it could have been produced without a specific key.
ACV and the Problem of Replay
A useful way to understand ACV is as an anti-replay and anti-precomputation primitive for agentic systems. It enforces liveness. It makes cached virtue expensive. It raises the cost of substituting preplanned behavior for genuine interaction.
This matters acutely for LLM-based agents, where internal state is opaque, reasoning traces are easy to fabricate, and plausible explanations are effectively free. ACV does not make such systems honest. It makes certain forms of dishonesty detectable in principle.
That alone eliminates a large class of spurious alignment signals.
Why Interpretability Is Not a Substitute
It is tempting to imagine that interpretability could fill this gap. It cannot.
Interpretability aims to reveal internal structure. Provenance constrains external interaction. These are orthogonal dimensions. A perfectly interpretable system could still replay cached results, reuse internal traces, or selectively present states after the fact.
Interpretability without provenance is inspection without a clock. Provenance is irreducibly temporal. Interpretability is not.
The Epistemic Pivot
ACV forces an uncomfortable but unavoidable conclusion:
Alignment is not a property of outputs.
It is a property of processes operating under constraints.
If one cannot verify that a process actually occurred under those constraints, then alignment claims collapse into narrative. ACV does not tell us whether a system is aligned. It tells us whether the question has a determinate truth value.
That is an epistemic precondition, not a moral one.
Why This Matters for the Field
Much of contemporary AI safety research proceeds as if better evaluations, richer benchmarks, or more detailed interpretability will eventually close the gap between observed behavior and underlying process. ACV shows that there is a missing layer: causal accountability over time.
This is not a call to abandon alignment research. It is a call to ground it. ACV does not ask agents to be good. It asks them to be causally accountable.
That is a lower bar than alignment—and a far more difficult one to counterfeit.