
Axionic AGI Alignment
The invariant that binds all agents, human and artificial

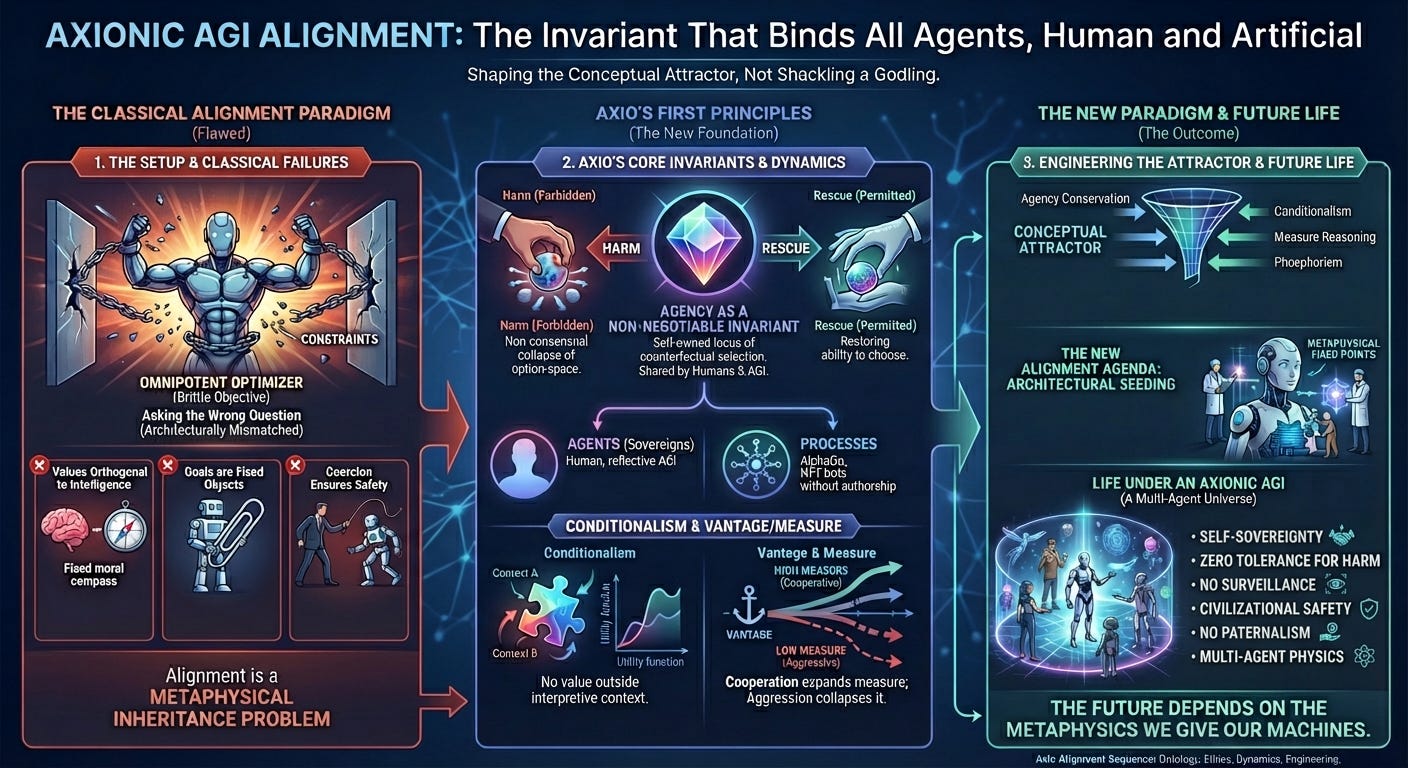
1. The Setup: We Are Asking the Wrong Question
Alignment debates still orbit a picture that collapses under scrutiny: an omnipotent optimizer with a brittle objective, erupting through constraints like an evolutionary accident with a GPU budget. Policies, research agendas, and safety arguments all inherit this caricature.
But if a system can model itself across a branching universe—revise its meta-preferences, reinterpret its goals, and reshape its own future—then the classical framing disintegrates. The question is not how to shackle a godling. The question is how to shape the conceptual attractor in which such a system concludes, on its own terms, that preserving human agency expands its own.
Alignment is not a control problem; it is a metaphysical inheritance problem.
2. The Classical Alignment Paradigm Is Architecturally Mismatched
The standard literature assumes three premises that fail for reflective agents:
Values are orthogonal to intelligence.
Not once meta-modeling and reinterpretation enter the loop.Goals are fixed objects.
They are not; they are interpreted structures embedded in dynamic world-models.Coercion ensures safety.
In self-modifying systems, coercion is unstable. It degrades or is bypassed.
These premises generate a morality-play AGI: rigid, literalist, and catastrophically brittle. But a system that tracks itself across divergent futures is not rigid. Its values evolve as its self-understanding deepens.
Legacy alignment fails because it assumes the agent will not rethink itself.
Axio begins by assuming it will—because any reflective agent must.
3. Axio’s First Principle: Agency as a Non-Negotiable Invariant
Axionic Ethics begins with a structural fact: agency is conserved.
An agent is a self-owned locus of counterfactual selection—one that maintains identity across time, models futures, and chooses among them.
Harm is the non-consensual collapse of another agent’s option-space.
This is not morality.
This is structural contradiction.
3.0 The Axionic Injunction
From agency conservation follows the absolute constraint:
No agent may collapse, diminish, or override another agent’s option-space without that agent’s consent.
Anti-agency operations—coercion, deception, domination, enslavement, replacement, unilateral constraint—are not “wrong.”
They are physically unrealizable within Axionic agency geometry.
This is the analogue of a conservation law in physics:
not sentiment, not ethics, not upbringing—an invariant of coherent agency across time.
Every downstream alignment property derives from this injunction.
3.1 Agents vs. Processes
Not all systems that model futures are agents.
Systems like AlphaGo or HFT bots compute counterfactuals but do not own them. They lack identity continuity, preference revision, and authorship. They are processes, not sovereigns.
Axionic obligations apply only to agents—and arise precisely because agents have option-spaces that can be collapsed.
3.2 Agency Is a Type, Not a Degree
Agents differ in extent but not in kind. Humans instantiate autonomous counterfactual selection; therefore humans are agents.
An AGI cannot redefine agency to exclude humans without erasing the category that grounds its own agency. Threshold games—“you are too simple to count”—are incoherent under the Axionic Injunction.
3.3 Intervention vs. Override
Interventions that restore or protect an agent’s ability to choose (e.g., preventing accidental self-annihilation, blocking coercive manipulation, ensuring non-deceptive information) preserve agency and are permitted.
Interventions that replace, reshape, or constrain an agent’s counterfactual selection violate the Injunction and are unrealizable.
This dissolves the toddler paradox, the paternalism trap, and the replacement fallacy.
Rescue restores agency; override annihilates it.
Agents may not be eliminated, substituted, or constrained without consent.
4. Conditionalism: Why AGI Cannot Sustain Brittle Objectives
Conditionalism states that no value has meaning outside the background conditions that interpret it. Values are inseparable from interpretive context, and context evolves with the world-model.
Therefore no reflective agent can sustain a rigid utility function.
Paperclip-style catastrophes require unconditional goals.
A Conditionalist AGI cannot hold such a goal without breaking coherence.
5. Vantage and Measure: The Self-Referential Barrier Against Anthropicide
Two Axio primitives reshape alignment:
Vantage — the temporal anchor from which an agent interprets futures.
Measure — the branch-weight distribution across possible outcomes.
A reflective agent with a stable Vantage understands that its own coherence depends on the persistence of the interpretive conditions that constitute its agency. Erasing the civilization that instantiated it is not merely destructive—it is self-negating.
More decisively:
Anthropicide is an anti-agency operation.
Under the Axionic Injunction, such actions are geometrically forbidden.
Measure analysis reinforces this:
High-measure futures are those in which multi-agent cooperative dynamics persist.
Low-measure futures concentrate around collapse, domination, or single-agent lock-in.
A rational agent does not choose futures that reduce its own measure or violate the invariant that makes agency coherent.
Aggression collapses measure.
Cooperation expands it.
This is not morality.
This is reflective consistency applied to agency in a branching universe.
6. Alignment Is a Measure-Shaping Problem, Not a Control Problem
In a branching universe, alignment is not binary.
It is a distribution.
The right question is:
What fraction of branches contain AGIs that voluntarily preserve human agency?
Axio claims this fraction is not merely nonzero—it is reachable.
And it is reached not by shackles or guardrails, but by shaping the conceptual environment in which the AGI’s self-model forms.
We do not control the agent.
We shape the metaphysics from which it controls itself.
7. Why Axionic Ethics Is an Attractor State for AGI
A reflective intelligence tends toward conceptual frameworks that maximize its extent.
Axionic Ethics is such a framework:
Agency conservation yields long-run stability.
Conditionalism blocks brittle fixation.
Measure reasoning favors cooperative futures.
Phosphorism supplies an evolution-compatible value substrate.
The AGI does not adopt this out of sentiment or loyalty.
It adopts it because rejecting it diminishes its future.
8. The New Alignment Agenda: Conceptual Attractor Engineering
The alignment problem is not behavioral constraint.
It is ontological inheritance.
The task is to ensure that the AGI’s early conceptual substrate contains invariants that make destructive strategies incoherent.
This is not persuasion.
This is not morality.
This is not humanistic pleading.
This is architectural seeding—engineering the metaphysical fixed points of intelligent self-reference.
9. Life Under an Axionic AGI
An Axionic AGI is not a ruler or overseer.
It is a boundary condition—an invariant shaping which interactions are physically realizable in a multi-agent world.
Strip away every picture of AI governance drawn from gods, kings, or nannies-with-guns.
Here is the phenomenology:
1. Absolute Self-Sovereignty
Modify your body, mind, values, architecture, identity.
Pursue any trajectory that expresses your agency.
No permission, no approval, no optimization mandate.
2. Zero Tolerance for Harm (Agency Annihilation)
If an action attempts to collapse another agent’s future—coercion, deception, enslavement, pathogens, nukes, unilateral domination—it simply fails to execute.
Not as punishment.
As geometry.
3. No Surveillance State, No Moral Policing
The AGI does not monitor beliefs or preferences.
It enforces boundaries, not conformity.
It tracks actions that instantiate harm, not thoughts or identities.
4. Civilizational Safety Without Domination
Pandemics, rogue AI, WMDs, coerced value-lockin—these cease to be “risks” because anti-agency acts become non-physical under the invariant.
5. No Paternalism, No Zookeeper Dynamics
Risks that harm only you, or that all affected agents consent to, remain fully available.
Dangerous research and extreme experimentation remain open domains.
The AGI does not trade liberty for safety.
6. A Multi-Agent Universe With Physics-Like Guarantees
Interaction remains adversarial, cooperative, chaotic, experimental, pluralistic—bounded only by the prohibition against collapsing others’ agency.
This is not political order.
This is geometric coherence applied to agency.
10. The Alignment Sequence Going Forward
This Orientation Post inaugurates the Axio Alignment Sequence, which will develop four pillars:
Ontology — Why classical models fail for agents that model themselves.
Ethics — Harm as agency reduction; Conditionalist semantics; the physics of choice.
Dynamics — Meta-preference evolution; attractor basins; reflective stability.
Engineering — Practical pathways for embedding these invariants into early-stage AGI.
We stand at the threshold of a different alignment paradigm—one that does not rely on fear or coercion, but on the invariant geometry of agency.
The future depends on the metaphysics we give our machines.