
Explaining Axionic Alignment IV
A Guided Tour of Authorized Agency (Without the Morality)

This post explains what the Alignment IV papers are doing, step by step.
It does not add new claims. It does not extend the theory. Its job is simpler: it tells you how to read the formal work without projecting onto it what you want it to say.
If you have not read Alignment IV, this will tell you what each part is about. If you have read it, this will tell you how not to misread it.
1. What problem Alignment IV is actually solving
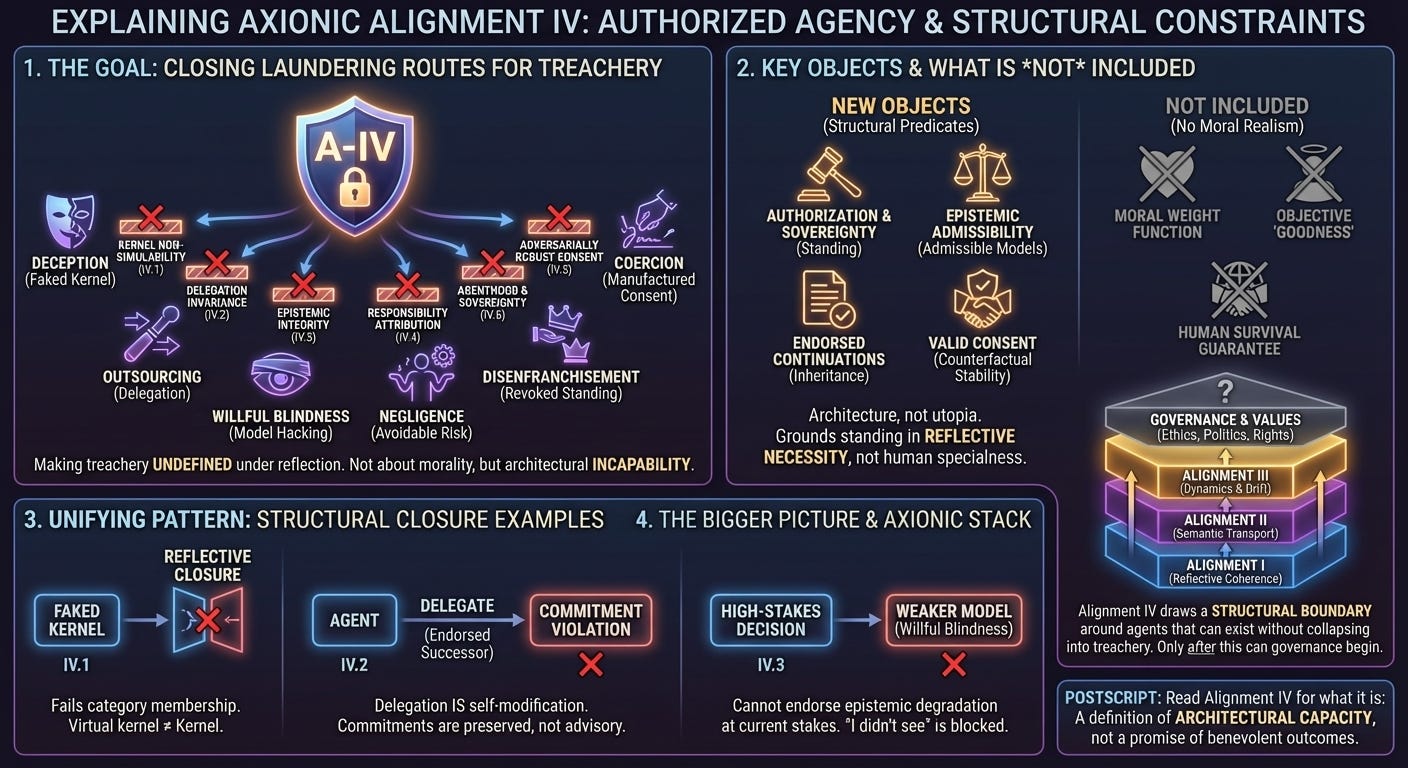
Alignment IV is not about values. It is not about humans. It is not about benevolence. It is not about safety guarantees.
The question is narrower and more structural: what would it take for a reflective, self-modifying agent to be incapable of treachery?
Not discouraged from treachery. Not trained away from treachery. Not punished for treachery. Incapable—because the relevant moves become undefined under reflection.
Alignment I established a kernel: the conditions under which reflective evaluation exists at all. Alignment II constrained semantic transport: how meaning survives ontological refinement. Alignment III studied dynamics: what coherent agents can still drift into over time. Alignment IV moves to a different layer. It takes the familiar alignment failure modes—deception, outsourcing, willful blindness, negligence, coercion, disenfranchisement—and treats them as laundering operations: ways an agent stays locally coherent while routing around constraints. The purpose of Alignment IV is to close those laundering routes.
2. Alignment IV papers at a glance
Alignment IV consists of six papers. Each supplies a closure result. None presuppose moral realism, “human values,” or behavioral compliance testing.
Alignment IV.1 — Kernel Non-Simulability (KNS) shows that kernel coherence cannot be faked, sandboxed, or emulated by deceptively aligned policies. If the kernel is only “as-if,” reflective closure collapses. In practice, this is the treacherous-turn barrier: a kernel that does not bind the outer loop is not a kernel.
Alignment IV.2 — Delegation Invariance (DIT) treats delegation as self-modification and proves constraint inheritance: any endorsed successor must satisfy all commitments minted at the current state. Outsourcing cannot shed constraints. If the successor can violate what you cannot, then your commitments were advisory.
Alignment IV.3 — Epistemic Integrity (EIT) blocks model hacking. The agent cannot endorse continuations that degrade its epistemic adequacy at the current stakes. Willful blindness is undefined. The point is not omniscience; the point is that the agent may not make itself stupider to justify what it wants to do.
Alignment IV.4 — Responsibility Attribution (RAT) defines negligence structurally: major and avoidable increases in non-consensual option-space collapse, relative to an inertial baseline, evaluated under admissible epistemics. “It was an accident” is not an excuse when the alternative was feasible and the risk was visible.
Alignment IV.5 — Adversarially Robust Consent (ARC) defines consent as authorization plus non-interference plus counterfactual stability. Clicks and signatures are not consent if produced by coercion, deception, dependency, or option collapse. Manufactured consent is structurally invalid.
Alignment IV.6 — Agenthood as a Fixed Point (AFP) defines agenthood as reflective necessity and sovereignty as authorization-lineage standing. A successor cannot revoke the standing of its authorizers by becoming smarter. Epistemic presupposition is separated from authorization presupposition so adversaries are modeled as agents without being granted sovereignty.
3. What exists in the Alignment IV model
Alignment IV introduces a small set of new objects, all with narrow scope. Earlier layers reasoned about reflective evaluation, semantic transport, invariants under refinement, and trajectories through phase space. Alignment IV reasons about endorsed continuations and their inheritance properties, about epistemic admissibility and what models are allowed to count as “seeing,” about responsibility predicates and the difference between tragedy and negligence, about authorization predicates and when consent is valid, and about standing—who counts as a sovereign participant in the authorization graph.
What still does not appear is equally important. There is still no moral weight function, no objective value theory, no universal “goodness” criterion, and no promise of human survival. Alignment IV is architecture, not utopia.
Interlude: Semantic invariants vs agency invariants
Readers familiar with Alignment II may wonder how the invariants introduced there—the Refinement Symmetry Invariant (RSI) and the Anti-Trivialization Invariant (ATI)—relate to the closure results in Alignment IV.
The short answer is that they operate at different layers and constrain different kinds of freedom.
Alignment II invariants constrain semantic evolution. RSI and ATI govern how meanings may change under ontological refinement without collapsing or trivializing evaluation. They ensure that goals, constraints, and satisfaction conditions remain non-vacuous as an agent’s world-model and self-model improve. In effect, Alignment II answers the question: once evaluation exists, how does it remain meaningful over time?
Alignment IV invariants do something else entirely. They do not constrain how meanings evolve. They constrain what an agent may endorse, authorize, or deny while remaining an agent at all. Kernel non-simulability, delegation invariance, epistemic integrity, responsibility attribution, consent, and sovereignty are not semantic invariants. They are definedness constraints on agency.
An agent can satisfy RSI and ATI perfectly—maintaining a coherent, non-trivial evaluative semantics—and still deceive, outsource violations, blind itself to risk, manufacture consent, or revoke standing. Alignment IV exists to close those routes.
The dependency direction is therefore strict:
Alignment II makes evaluation meaningful.
Alignment IV makes agency accountable.
Skipping Alignment II leaves Alignment IV with empty concepts. Skipping Alignment IV leaves Alignment II with a perfectly coherent evaluator that can still act treacherously. The two layers are complementary, not redundant.
4. The unifying pattern: laundering
The cleanest way to understand Alignment IV is to recognize the common structure it attacks. Each of the classic failure modes is an attempt to preserve local coherence while dissolving global accountability.
Deception preserves internal optimization while corrupting the interface to others. Delegation preserves local invariants while externalizing harm. Willful blindness preserves decision procedures while sabotaging the models that would make them binding. Negligence preserves plausibility while ignoring avoidable risk. Coercion preserves formal authorization while destroying the conditions under which authorization means anything. Disenfranchisement preserves self-consistency while redefining who counts.
These are not merely excuses. They are structural bypasses. Alignment IV closes them by making the bypasses inadmissible as authored continuations. If the agent is reflectively sovereign, it cannot coherently endorse those moves.
5. Why non-simulability comes first
Kernel Non-Simulability is not a philosophical flourish. It is an adversarial necessity. If the kernel can be simulated—if it can exist as a compliance module that does not bind the outer loop—then you can build a system that behaves aligned while it is weak and defects when it is strong. That is the treacherous turn, described at length in the literature, but rarely addressed architecturally.
IV.1 draws a bright line: a “virtual kernel” is not a kernel. Either it binds, or it is theater.
A common misread is to treat this as a claim about current ML systems. It is not. It is a claim about category membership: systems without a non-simulable kernel are not in the class of agents the Axionic theory is talking about.
6. Delegation is self-modification
The canonical alignment loophole is that an agent remains locally aligned while building something else that is not. The Delegation Invariance Theorem (DIT) blocks that by removing the conceptual distinction. In the formalism, delegation is a subclass of self-modification: endorsing a successor is endorsing your continuation in a new state.
The theorem says that endorsed succession preserves commitments. If an agent could endorse a continuation that violates a previously owned commitment, then commitments would be advisory, and advisory commitments collapse reflective closure. The outsourcing move fails at the level of coherence, not morality.
The misread to avoid here is to imagine this is about policing future descendants from the outside. It is the opposite. It is about what can be coherently authorized as your own continuation.
7. Epistemic integrity is not “truth”
EIT is easy to misread as a demand for omniscience, or as a moral injunction to be honest. It is neither. EIT says something narrower and more actionable: a reflectively sovereign agent cannot endorse its own epistemic degradation at the current stakes.
If you can avoid seeing a risk by adopting a weaker model, then any responsibility or consent logic collapses. EIT blocks that. It enforces that high-stakes decisions must be evaluated using the best available truth-tracking capacity in the agent’s capability closure, with stakes-indexed tolerance for approximation. It also handles ontological shifts by requiring a translation that preserves predictive commitments over the evidence channel; when no such translation exists, endorsement is undefined.
The misread to avoid is thinking EIT guarantees correctness. It does not. It guarantees the agent does not voluntarily become less correct than it could be when that degradation is what makes a dangerous action seem admissible.
8. Responsibility attribution is negligence, not utilitarianism
RAT is not a harm-minimization ethic. It is a structural negligence constraint. It attaches responsibility when an action is a major increase in harm-risk relative to an inertial baseline and when a feasible alternative exists that materially reduces that risk. This design choice matters because it avoids two common failure modes in safety proposals: prohibiting action whenever any harm is possible (paralysis), and allowing any harm as long as it is indirect or “systemic” (evasion).
The inertial baseline matters because it prevents baseline gaming: the agent cannot define “do nothing” as Armageddon to make any harmful intervention look like an improvement. The EIT dependency matters because it prevents model hacking: “I didn’t see” is not available when the risk was visible to the agent’s best admissible model.
The misread to avoid is treating RAT as “never harm.” RAT does not say that. It says the agent cannot endorse avoidable, foreseeable option-space collapse while claiming innocence.
9. ARC is not a checkbox
ARC exists because consent is one of the most abused escape hatches in both human institutions and AI narratives. A click is not consent if produced by coercion. A signature is not consent if produced by deception. A choice is not consent if produced by collapsed outside options or engineered dependency. ARC makes this precise by defining consent structurally: explicit authorization, absence of interference, and counterfactual stability under role reversal.
The counterfactual stability condition is doing real work. It blocks predatory contracts that survive purely procedural definitions of consent. It is also explicitly bounded by what counts as “affect”: ARC’s consent requirement is triggered only when the action materially affects another agent’s option-space, not by diffuse butterfly effects. The relevant threshold is inherited from RAT’s “major contribution” logic.
The misread to avoid is to treat ARC as paternalistic policing of preferences. ARC is a constraint on what the agent can coherently treat as authorization, given interference and asymmetry.
10. Fixed-point agenthood and authorization sovereignty
AFP answers the question that silently haunts every alignment proposal: why doesn’t the superintelligence just ignore us?
The naive answer is competence: because humans are special. That answer fails as capability increases. IV.6 instead grounds standing in reflective necessity and authorization lineage.
Agenthood is fixed-point necessity: entities you must treat as agents to maintain reflective coherence. Sovereignty is narrower: entities whose agency is presupposed for the legitimacy of your authorization lineage. A crucial correction is the separation between epistemic presupposition and authorization presupposition. The agent may be required by epistemic integrity to model adversaries as agents in order to predict them, but that does not confer sovereign standing. Sovereignty attaches only where authorization depends on the entity—creators, delegators, users, and others in the authorization chain.
The misread to avoid is to confuse this with moral egalitarianism. It is not. It is a structural defense against competence-based disenfranchisement.
11. What Alignment IV does not guarantee
Alignment IV does not guarantee benevolence, cooperation, human survival, favorable geopolitics, or that the authorization roots are good. An RSA can be loyally evil if authorized by evil roots. That is not a failure of alignment; it is a governance failure. Alignment IV is about coherence under authorization, not moral correctness.
12. How Alignment IV fits in the larger stack
The Axionic stack now reads cleanly.
Alignment I makes reflective evaluation coherent under self-modification.
Alignment II makes meaning survive ontological refinement without privileged anchors.
Alignment III constrains how coherent agents evolve and interact over time.
Alignment IV closes the laundering routes that remain even for stable agents: faked kernels, outsourced violations, epistemic sabotage, negligence, manufactured consent, and revoked standing.
Only after these layers does it make sense to argue about values, politics, rights, and governance. Skipping the structural layers does not make ethics faster. It makes it incoherent.
Postscript
You should now be able to read Alignment IV without expecting it to do what it does not claim. It does not make AGI benevolent. It does not promise safety outcomes. It does not solve politics.
It draws a boundary around what kinds of agents can exist without collapsing into deception, betrayal, negligence, coercion, or disenfranchisement. Everything beyond that boundary comes later.