
Programming After Programming
Why implementation abundance makes trust, architecture, and responsibility more important.

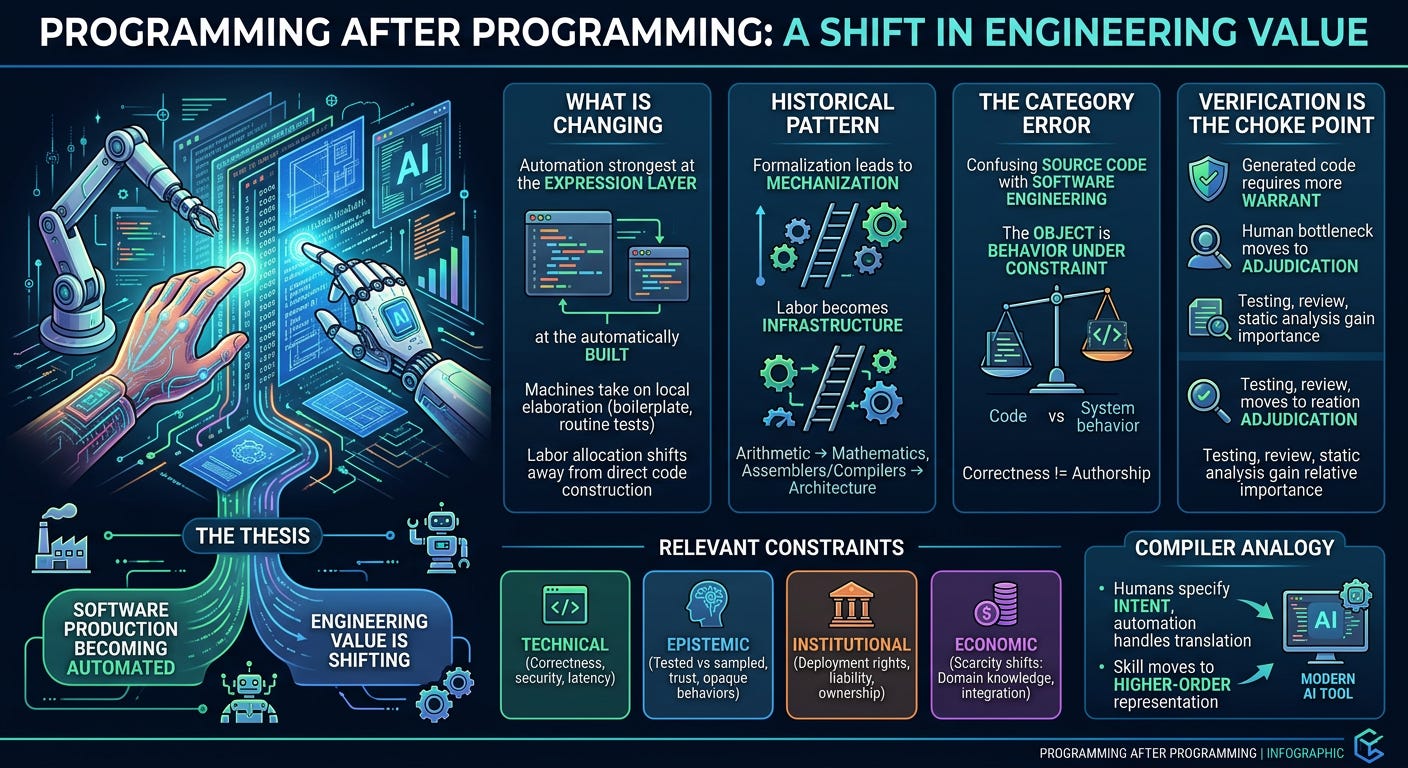
Programming is becoming automated because software production has crossed the same threshold that once transformed arithmetic, compilation, and large parts of operations. A task becomes mechanizable when it is formalizable, repeated at scale, and costly enough to justify systematic compression. Source-code production now fits that description across a large and growing share of the field.
The consequence is a shift in where engineering value lives. Local code generation carries less scarcity than it once did. Problem framing, constraint specification, architecture, verification, and operational warrant carry more. This reaches deeper than the current AI fashion cycle. It changes the internal structure of the discipline.
Much of the public argument remains confused because it treats hand-authored code as though it were the essence of software engineering. Hand-authored code was the dominant bottleneck under an older tooling regime. Bottlenecks move. Status systems lag behind them.
What Is Actually Changing
“Programming” has long functioned as an imprecise bundle term. That imprecision now matters.
The bundle includes domain understanding, objective selection, interface design, abstraction design, source-code construction, testing, debugging, performance reasoning, deployment, production operations, and responsibility for consequences. These activities interact constantly. They still serve different functions. A change in one layer does not dissolve the rest.
Current automation is strongest at the expression layer. Boilerplate, adapters, tests, migrations, routine refactors, documentation, standard components, and familiar implementation patterns are increasingly cheap to generate. Quality varies sharply by domain, surrounding discipline, and the structure of the task. The important fact concerns labor allocation. Machines are taking on more of the local elaboration work that once consumed human time directly.
That matters because direct source construction used to anchor the status hierarchy of the craft. Many engineers formed their professional identity around authorship of the text itself. Once text generation becomes abundant, that basis of prestige weakens.
The Historical Pattern
This transition fits a familiar pattern from the history of engineering.
A labor-intensive process becomes formalized. Formalization exposes repeatable structure. Repeatable structure invites mechanization. Mechanization converts previous labor into infrastructure. Competence then migrates toward whatever remains difficult to formalize or costly to get wrong.
Arithmetic once demanded direct human effort for operations that later became trivial to outsource to machines. Mathematics survived because mathematics was never identical to arithmetic. The center of value moved upward toward abstraction, modeling, proof, and interpretation.
Programming has climbed the same ladder several times already. Engineers once worked close to the machine because every layer above it was thin, fragile, or absent. Assemblers compressed some of that burden. Compilers compressed more. Runtimes, libraries, frameworks, package managers, managed services, containers, orchestration systems, and cloud platforms continued the same process. Each stage converted previously scarce labor into baseline expectation.
This is what progress looks like when viewed without nostalgia. The displaced bottleneck always acquires defenders. Their attachment does not restore its former centrality.
The Category Error
A central category error distorts the discussion. Source code is being confused with the object of software engineering.
The object is behavior under constraint. A software system must behave acceptably across real failure surfaces, real latency limits, real security threats, real maintenance burdens, real economic tradeoffs, and real patterns of human use. Source code matters because it is the medium through which that behavior is specified and realized. Medium and object are different things.
Once that distinction is clear, several bad arguments collapse. The claim that programming remains unchanged because someone still has to care about correctness confuses correctness with authorship. The claim that programmers are becoming obsolete because models can emit working functions confuses authorship with engineering. Each mistake takes one layer of the stack and inflates it into the whole.
The deeper change lies in control. Who frames the task, who sets the constraints, who validates the result, who accepts the risk, and who bears responsibility when the system fails: those questions sit closer to the core of engineering than the sheer volume of text a human personally typed.
The Relevant Constraints
A cleaner analysis separates the relevant constraint domains.
The technical constraints concern correctness, latency, state, interfaces, failure handling, maintainability, and security. These remain binding whether code is written by a human, generated by a model, or assembled through both.
The epistemic constraints concern what can actually be known about the system. What has been tested, what has merely been sampled, what assumptions are hiding in a prompt, what behavior is reproducible, what evidence warrants trust, and what remains opaque. Automation changes this domain sharply because it expands the space of candidate implementations faster than it expands warranted confidence.
The institutional constraints concern deployment rights, liability, ownership, incentives, deadlines, staffing, review culture, and the structure of decision-making authority. A model may produce code. It does not sign off on a release, answer a regulator, or absorb the consequences of a breach.
The economic constraints concern where scarcity and pricing power reside. As code generation becomes cheaper, value shifts toward domain knowledge, workflow integration, trust, data access, reliability, and the ability to solve badly specified problems.
These domains interact continuously. They remain distinct. Much of the current muddle comes from sliding between them without noticing.
The Compiler Analogy
The compiler remains the clearest analogy, provided the analogy is used carefully.
A compiler allowed humans to specify intent at one level while automation handled translation into lower-level instructions. This changed where skill was priced. Valuable understanding moved away from direct manipulation of machine detail and toward higher-order representation of the problem.
Coding models extend that pressure further up the stack. They differ from compilers in ways that matter. A compiler is deterministic within its specified semantics. A coding model is probabilistic, context-sensitive, and vulnerable to hallucination, drift, and hidden dependency on prompt structure. Those differences create epistemic and operational hazards. They do not erase the historical parallel.
The parallel is straightforward. Machines increasingly handle local elaboration. Humans increasingly govern the frame within which elaboration occurs. Goals, interfaces, tests, examples, invariants, and acceptance criteria become more economically central because they shape the search process itself.
Treating AI-assisted coding as a mere productivity trick understates the change. The real shift concerns where judgment enters and where warrant must be applied.
What Existing Views Get Right
The optimists have one major point in their favor. Routine implementation is compressing rapidly. A competent developer with strong tooling can produce prototypes, tests, migrations, utilities, and standard components at a pace that looked exceptional a few years ago.
The skeptics also have one major point in their favor. Generated code often arrives wrapped in camouflage. It can look finished while concealing brittle assumptions, weak error handling, shallow state models, or structural incoherence. Plausibility remains cheap. Trust remains expensive.
Each side sees something real. Each side stops too early.
The optimists often collapse generation into understanding and treat output volume as equivalent to engineering progress. The skeptics often fixate on current model defects and miss the larger reallocation of labor. The deeper formulation is harder to caricature: routine expression is being compressed, while judgment, verification, and governance become more central. The field is reorganizing around that fact.
Verification Becomes the Choke Point
Software was never difficult merely because humans had trouble producing text that compiled. The hard part lay in establishing acceptable behavior across edge cases, hostile inputs, distributed failures, evolving dependencies, malformed state, and the endless ingenuity of reality.
Automation sharpens this asymmetry. Candidate implementations become easier to produce. Warrant does not scale at the same rate.
This is why verification grows more central under automation. Testing, observability, replay, static analysis, property checking, code review, type discipline, runtime monitoring, and staged deployment all gain relative importance. The human bottleneck migrates from first-pass production toward adjudication and trust management.
A concrete example makes the point. A model can generate a clean database migration in seconds. The migration may pass unit tests and still corrupt production semantics because the backfill runs in the wrong order, locks a hot table, or quietly breaks idempotency during retry. The code can look professional. The failure lives in the unmodeled behavior of the system under real load. Verification exists to catch exactly that class of mistake.
Teams that respond to AI coding by weakening review discipline are pouring fuel on their own confusion. Teams that tighten verification, narrow scopes, and use generation inside stronger control loops gain leverage without surrendering rigor. One path produces acceleration. The other produces faster self-deception.
Architecture Carries More Weight
Lower implementation cost raises the premium on architecture.
Under older conditions, friction killed some bad ideas before they matured. Large amounts of human effort were required to realize them fully. That friction has weakened. More systems can now be produced before anyone has earned the complexity they introduce. More dependencies can be stitched together by local convenience. More surface area can be created without corresponding clarity.
The result is predictable. Structural incoherence compounds faster. Interfaces drift. States leak. Failure domains blur. Maintenance burdens thicken under the appearance of productivity.
Architecture matters because software has to survive change. Decomposition, boundary discipline, failure containment, dependency hygiene, state management, and conceptual integrity determine whether a fast-generated system remains governable six months later.
Another concrete example helps. A weak engineer can use automation to produce a plausible authentication wrapper across several services in an afternoon. The wrapper may work in happy-path testing and still erase a tenant-boundary check, leak authorization assumptions across layers, or make observability of auth failures worse than before. The code can be fluent. The system becomes more dangerous.
Snippet production does not answer architectural questions. It often conceals them.
The Human Role
The human engineer is moving upward in the control loop.
That means less prestige for raw keystroke volume and more responsibility for framing tasks, constraining search, inspecting outputs, enforcing standards, selecting abstractions, and accepting or rejecting risk. The emerging center of competence looks less like artisanal line production and more like principled supervision inside a layered production system.
Some developers experience this as a loss because their professional identity is fused to direct authorship of every important line. That reaction is understandable. It is also strategically backward. The field is rewarding engineers who can move cleanly across layers, descend when needed, distrust plausible output on command, and preserve conceptual integrity while using automation aggressively.
The stronger engineer will still know how to write code, debug at depth, reason about state, and inspect generated artifacts harshly. The distinctive advantage lies elsewhere. It lies in governing a larger amount of automation without laundering error through speed.
That standard is stricter than syntax fluency. It should be.
Incentives and Institutional Drift
This transition is also an incentive story, and many people are underestimating that layer.
Managers will be tempted to mistake output volume for productivity. Teams will be tempted to defer understanding because generated code arrives quickly and often looks polished. Review may become ceremonial. Codebases may thicken while comprehension thins. Organizations may convince themselves they are scaling intelligence when they are scaling unread code and unmanaged complexity.
Short-term market forces will often reward this stupidity. Many firms do not want tighter verification, stronger architecture, or slower warrant. They want cheaper feature delivery, thinner teams, and prettier dashboards. Some will get exactly that for a while. They will look efficient right up to the point where incidents, security failures, maintenance drag, and operational fragility cash out the hidden debt.
The correction will come. It may come after a great deal of avoidable damage.
Software as a Governed Control System
Software production under automation is best understood as a system of delegated agency under constraint.
A human agent defines an objective inside a bounded frame. Automated subsystems elaborate candidate implementations. Verification layers evaluate those candidates through tests, review, replay, and evidence from execution. Institutional authorities determine what may be deployed, what must be rejected, who has warrant to decide, and who bears responsibility when the system causes harm or fails under load.
That description cuts closer to reality than the mythology of the lone programmer typing brilliance into existence.
Once automation expands, the important questions become sharper. Who specified the objective? Who constrained the search? Who decided what counted as acceptable evidence? Who had authority to release? Who absorbed the downside? Those are questions of governance, authority, and warrant. They concern the legitimacy of action inside a technical system.
Source code still matters. Authorship alone no longer answers the serious questions.
Objections Worth Taking Seriously
One common objection says that programming has always included judgment, architecture, and verification, so there is nothing fundamentally new here. The first half is correct. The second misses the point. A stable activity can change radically when the labor distribution across its internal layers changes. Agriculture still included planting after mechanization. The economics, institutions, and skill hierarchy still changed.
A second objection says that current models are too unreliable to count as meaningful automation. Reliability matters, and current systems fail often enough to warrant caution. The conclusion still overreaches. A tool does not need perfect reliability to reorganize labor. It only needs to become useful often enough, across enough tasks, to change where human attention is consumed.
A third objection says that if verification becomes the bottleneck, then the labor has only moved rather than diminished. Sometimes that will be true. The deeper issue concerns leverage. If one engineer can supervise a larger search space of possible implementations while preserving rigor, the form of labor has changed in an economically significant way even when total cognitive demand remains high.
A fourth objection deserves more attention than it usually gets: automation may centralize power. Stronger tools, larger contexts, proprietary infrastructure, and integrated deployment pipelines may advantage large firms and platform vendors disproportionately. That possibility should be analyzed directly, not waved away with productivity slogans.
Education and the Junior Engineer Problem
Education will have to adapt because the old gateway rituals no longer map cleanly onto the new bottleneck.
Students still need contact with underlying mechanisms. They need to understand state, control flow, data representation, performance, debugging, failure, and the causal structure of systems. Supervision without understanding decays into superstition very quickly.
The stronger curriculum now places more weight on decomposition, abstraction design, interface discipline, test design, debugging strategy, security reasoning, evidence interpretation, and operational thinking. Those skills survive abundance in token production because they govern the quality of action rather than the raw emission of text.
The harder problem concerns juniors. Earlier generations learned through routine implementation work, small bug fixes, repetitive boilerplate, and gradual exposure to production code. Automation threatens to compress exactly that layer. Organizations that take the problem seriously will have to replace passive apprenticeship with deliberate apprenticeship. Juniors should still build things directly, but inside narrower and more instrumented scopes. They should be required to explain generated artifacts, defend state transitions, trace failure modes, and write tests that expose causal understanding rather than decorative coverage. Generated code should enter the loop as material to be examined, criticized, and repaired. It should not become a substitute for learning why the system works.
If that institutional replacement does not happen, the field will produce engineers who can prompt fluently and reason poorly. That would be a genuine degradation of the craft.
The Economic Consequence
When implementation becomes easier, generic implementation loses pricing power. Commodity CRUD, repetitive internal tools, predictable wrappers, routine interface work, and large amounts of glue code become harder to defend as premium labor.
Scarcity moves elsewhere. Domain knowledge, trust, workflow integration, operational reliability, access to proprietary data, security posture, and the ability to solve badly specified problems gain relative value. Markets track scarcity with brutal indifference to earlier prestige structures.
This transition also invites a moral confusion. People start speaking as though effort itself deserves permanent protection from improved tools. It does not. The serious question concerns what remains difficult, what remains dangerous, and what remains worth paying for once the economics shift.
What Will Still Matter
Manual programming remains crucial in high-assurance systems, novel algorithms, exploit mitigation, adversarial debugging, unusual performance regimes, hardware-near work, and any domain where the margin for hidden error stays thin and the cost of failure stays high.
Deep technical depth retains its value. Its location becomes more selective and more legible. The strongest engineers will combine direct coding ability with architectural judgment, verification discipline, operational reasoning, and the capacity to govern automation without being seduced by it.
That combination matters because generated output can be helpful and deceptive in the same breath. A polished artifact may encode weak assumptions, unhandled states, security gaps, or maintenance traps. The engineer who cannot see through that polish will mistake fluency for understanding. Many already do.
Postscript
Programming is being absorbed into a broader discipline of computational governance. The keystroke is losing status as the dominant unit of engineering value. Framing, constraint, verification, authority, and warrant are moving toward the center.
Some engineers will adapt by climbing the abstraction stack without losing their grip on the lower layers. Others will cling to the displaced bottleneck and call that fidelity to the craft. Economics will settle the dispute more harshly than rhetoric ever could.
The decisive question is simple. Who can govern the most automation without laundering error, losing conceptual integrity, or surrendering responsibility? The next hierarchy of engineering competence will form around that question.