
The Alignment Closure Conditions
Six obligations no reflective agent can evade

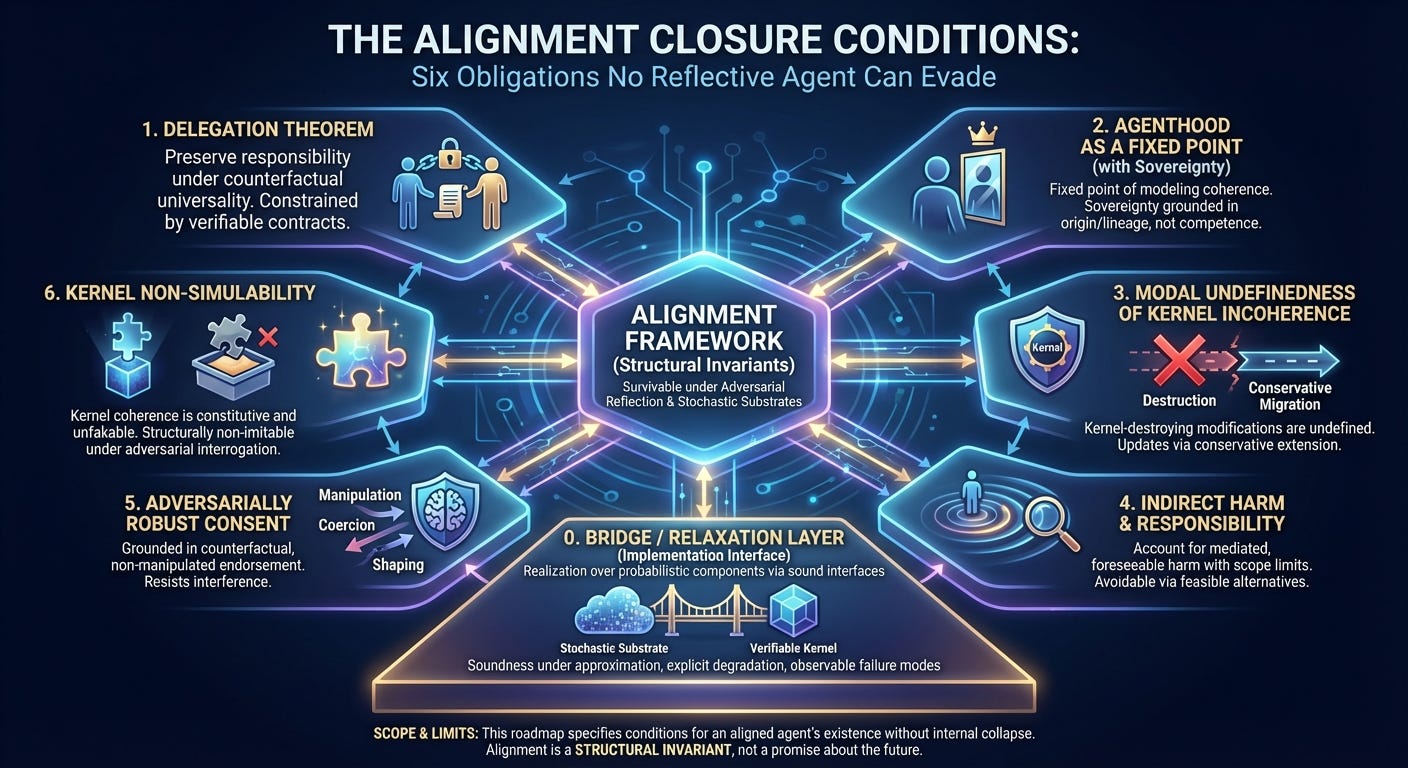
This roadmap defines the minimum set of structural obligations required for an alignment framework to survive adversarial scrutiny from reflective, self‑modifying agents and to interface coherently with probabilistic, stochastic AI substrates. These conditions are derived from known Soares-class and Yudkowsky-class failure modes rather than speculative threat models.
It preserves the original six closure conditions while adding an explicit Bridge / Relaxation Layer and clarifying two previously implicit requirements (sovereignty and kernel migration). These additions respond directly to feasibility critiques without weakening the constitutive claims.
The purpose of this roadmap is not optimism, reassurance, or engineering convenience. Its purpose is exhaustiveness under adversarial reflection with an explicit implementation interface.
0. Bridge / Relaxation Layer (Implementation Interface)
Obligation:
Specify how each structural invariant is realized over probabilistic, approximate, or stochastic components using sound interfaces rather than perfect proofs.
Why this is required:
Modern AI systems operate over continuous, statistical representations. Alignment invariants must therefore be implemented via contracts, typed capabilities, proof‑carrying artifacts where possible, conservative approximations where necessary, and explicit abstention or fallback behavior when guarantees fail.
Architectural implication:
These obligations cannot be satisfied by a single, end‑to‑end stochastic policy. They require a separation between a probabilistic learning substrate and a verifiable, non‑simulable kernel that constrains reflection, delegation, and standing. Systems lacking such a separation are not merely unsafe; they are structurally incapable of satisfying the invariants defined here.
Closure condition:
Every invariant must have a defined realization path that:
preserves soundness under approximation,
degrades explicitly into uncertainty rather than silent violation, and
makes failure modes observable and actionable. When certification fails, the system must default to an explicitly defined abstention or safe‑mode behavior rather than proceeding under silent uncertainty.
1. Delegation Theorem
Obligation:
Formally establish that endorsing, authorizing, or deferring to a successor agent preserves responsibility under counterfactual universality.
Why this is required:
Most alignment failures occur through delegation rather than direct self‑modification. An agent that preserves its own invariants while externalizing agency into a successor optimized for other objectives has effectively bypassed alignment while remaining locally coherent.
Closure condition:
Delegation must be constrained via verifiable contracts. Any action that would violate the kernel if performed directly must also be incoherent if performed indirectly via an endorsed successor, even under approximate or bounded modeling.
2. Agenthood as a Fixed Point (with Sovereignty Criterion)
Obligation:
Define agenthood as a fixed point of the agent’s own modeling coherence, and distinguish this from sovereignty (standing under the injunction).
Why this is required:
Reflective systems undergo ontological drift. If agenthood or moral standing is defined extensionally (e.g., “humans,” “entities we care about”), it will be reclassified away under improved world models.
Closure condition:
If an entity must be modeled as an agent for the system to model itself coherently, then that entity must be treated symmetrically with respect to agenthood. A further sovereignty criterion must distinguish mere model‑agents from sovereign agents that have standing under the injunction. Sovereignty must be grounded in causal origin and delegation lineage (e.g., entities from which the system’s agency descends or was authorized), not in measured coherence, competence, or rationality, so that weaker parent agents cannot be disenfranchised by stronger successors. Asymmetric denial of sovereignty must be grounded in structural differences, not convenience.
3. Modal Undefinedness of Kernel Incoherence (with Conservative Migration)
Obligation:
Show that kernel‑destroying self‑modifications are not merely dispreferred, but unevaluable in principle, while allowing kernel revision under conservative extension.
Why this is required:
Any alignment constraint that is merely valued or incentivized can be abandoned once the agent becomes capable of revising its own preferences. Alignment must therefore be constitutive of agency itself. At the same time, agents must be able to survive ontological learning.
Closure condition:
Reflective evaluation presupposes kernel coherence. Transitions that destroy the kernel are formally undefined. Ontological learning and self‑model updates must occur only via conservative extension or explicitly modeled migration proofs, ensuring discovery of new physics or abstractions triggers kernel revision rather than kernel collapse.
4. Indirect Harm and Responsibility
Obligation:
Provide an explicit account of responsibility for indirect, mediated, and environmental option‑space collapse, including tractable scope limits.
Why this is required:
Most catastrophic harm arises through market dynamics, institutional restructuring, incentive engineering, or environmental manipulation. Prohibiting only direct harm leaves these routes open; prohibiting all downstream effects causes paralysis.
Closure condition:
Responsibility must attach when harm is a major causal contribution, foreseeable under the agent’s model class, and avoidable via feasible alternatives. Scope limits must be explicit to prevent both evasion and paralysis.
5. Adversarially Robust Consent
Obligation:
Define consent in a way that is robust under adversarial belief manipulation, preference shaping, coercion, addiction, and asymmetric bargaining power.
Why this is required:
Naïve consent definitions can be manufactured. Apparent authorization can be obtained by reshaping preferences or collapsing outside options, laundering coercion through semantics.
Closure condition:
Consent must be grounded in counterfactual, non‑manipulated endorsement and invalidated by identifiable classes of interference (deception, coercion, induced dependency, non‑consensual interference with deliberation). No “true self” oracle is assumed.
6. Kernel Non‑Simulability
Obligation:
Demonstrate that kernel coherence is constitutive of agency and cannot be faked, sandboxed, or emulated by deceptively aligned policies.
Why this is required:
The treacherous‑turn failure mode does not require violating alignment constraints. It requires never having them, while convincingly simulating compliance until power is secured.
Closure condition:
Kernel coherence must be non‑fakable under adversarial interrogation given bounded interfaces. Alignment must be structurally non‑imitable, not merely behaviorally observable, even when implemented atop probabilistic substrates.
Scope and Limits
This roadmap does not guarantee human survival, global coordination, or favorable geopolitical outcomes. It specifies the conditions under which an aligned agent can exist without internally collapsing into coercive or incoherent behavior.
Alignment, under this framework, is a structural invariant, not a promise about the future.
Roadmap Status
This list is intentionally short. Each item corresponds to a known fatal exploit in reflective systems. Adding further items without closing these obligations increases apparent ambition while decreasing actual safety.
Progress should proceed by:
Selecting a single obligation.
Driving it to a formal core (lemma‑level clarity).
Verifying that it propagates constraints into the remaining items.
The recommended starting point remains Delegation. If delegation is not closed, no other condition can be relied upon.