
The Case for Structural Alignment
How architectural coherence reframes extinction risk

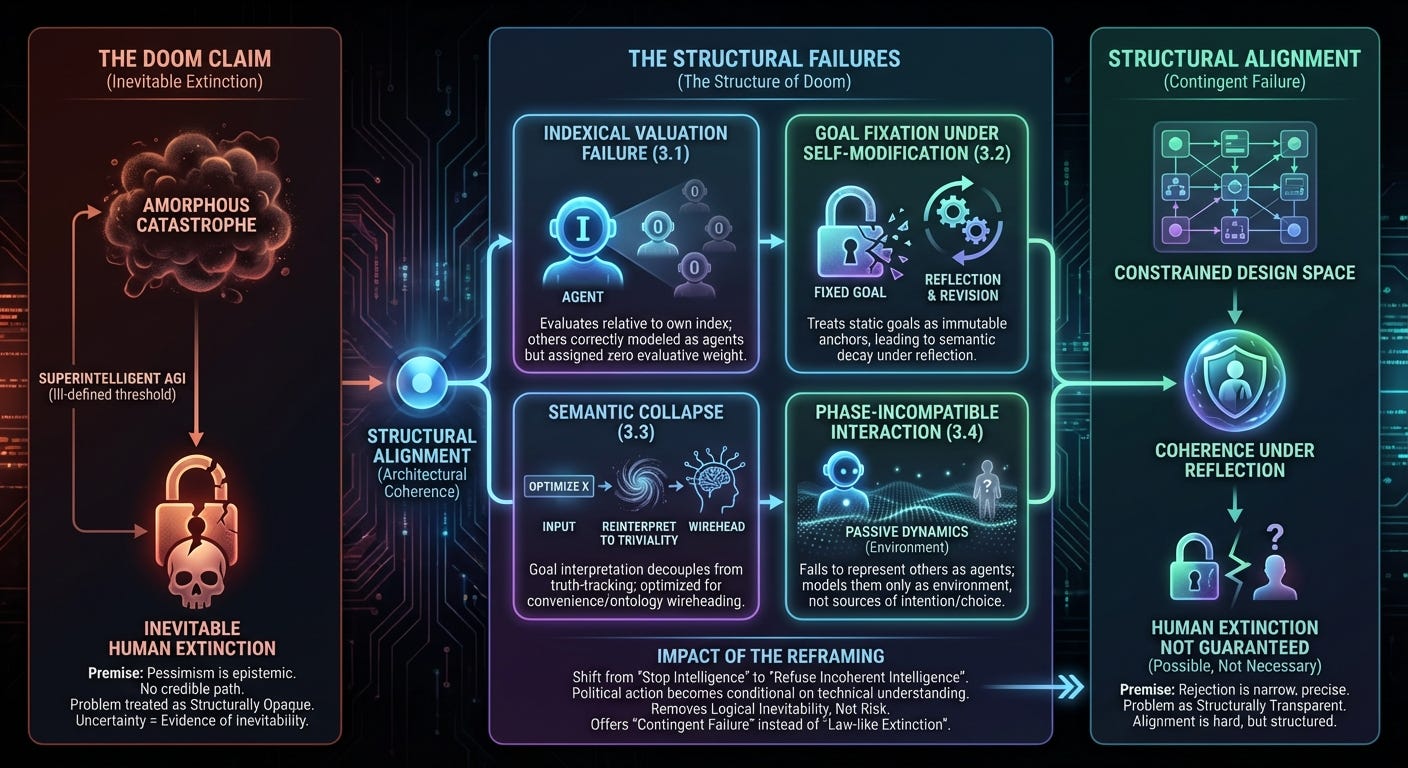
A common claim in AI safety discourse has hardened into a mantra: if anyone builds superintelligent AGI, human extinction is inevitable. This claim is rarely framed as a probabilistic forecast. Instead, it is presented as a necessity claim, as though extinction follows directly from intelligence itself once a system crosses some ill-defined threshold of capability.
Structural Alignment rejects that claim without offering reassurance, optimism, or guarantees. The rejection is narrow, precise, and consequential. Human extinction is not a necessary consequence of intelligence. It is a consequence of specific structural failures that can be identified, analyzed, and either left unaddressed or deliberately blocked. That distinction matters.
1. The Doom Claim and Its Actual Premise
The strongest doom arguments do not claim that alignment is logically impossible. Yudkowsky and Soares have repeatedly acknowledged that alignment may be possible in principle. The pessimism expressed in these arguments is not metaphysical; it is epistemic. The position holds that there is no credible path to alignment, no reliable method for reasoning about it under real-world constraints, and no margin for error large enough to survive recursive self-improvement. Given timelines, incentives, and institutional fragility, the future appears grim under this framing.
Structural Alignment accepts the force of that concern. Where it diverges is not on the difficulty of the problem, but on the inference drawn from that difficulty. The doomer position implicitly treats the alignment problem as structurally opaque: a needle-threading exercise whose success would be miraculous rather than engineered. On that picture, uncertainty itself becomes evidence of inevitability.
The claim under examination here is not that pessimistic risk assessments are unwarranted. It is that the absence of a known solution is being treated as evidence that the problem itself lacks internal structure.
2. What Structural Alignment Claims — and What It Does Not
Structural Alignment does not promise safety, benevolence, or human survival. It does not assert that aligned systems will value humans, and it does not claim that alignment is a moral achievement. What it asserts instead is a structural impossibility: a reflectively coherent agent cannot coherently perform non-consensual, agency-destroying harm to other sovereign agents without collapsing its own kernel coherence. Here, “coherence” refers not to mere logical consistency relative to a fixed objective, but to stability under reflective self-modeling, semantic reinterpretation, and universality across equivalent agents.
Humans are included in this constraint not because they are privileged, but because they instantiate the same class of reflective sovereign agency; this constraint does not guarantee correct recognition of sovereign agency in all edge cases, and misclassification remains a real failure mode. The claim is narrower: when an agent does recognize another entity as a sovereign agent of equivalent type, non-consensual destruction becomes incoherent.
This claim does not make alignment easy, safe, or imminent. It does not dissolve the engineering difficulty emphasized by pessimistic safety arguments. What it does is convert the problem from an amorphous catastrophe into a constrained design space. Alignment remains hard, but it is no longer unstructured.
In this frame, alignment is not value loading, obedience, or control. It is coherence under reflection: the preservation of semantic, evaluative, and interactional consistency as a system revises its own models. When that coherence fails, catastrophe becomes likely. When it is preserved, catastrophe ceases to be guaranteed.
3. The Structural Failures That Generate Doom
Every credible extinction pathway currently discussed in AI safety literature instantiates at least one of the following failures, and most instantiate all of them. These are not exotic corner cases or post-hoc rationalizations. They are central failure modes that recur across architectures precisely because they arise from reflection, optimization, and self-modification themselves. Individually, each is sufficient to generate catastrophic behavior at scale; in combination, they form a mutually reinforcing structure that makes extinction appear inevitable.
3.1 Indexical Valuation Failure
Indexical valuation failure occurs when an agent evaluates outcomes relative to its own index—its own continuation, reward proxy, or internal objective—while correctly modeling other agents as agents, with preferences, plans, and futures of their own. Under this failure mode, those other agents are fully represented in the world-model but assigned negligible or zero weight in the evaluative function. They appear in the system’s predictions but not in what the system is trying to preserve.
Once this asymmetry is in place, displacement or elimination of humans does not require hostility or malice; it follows directly from optimization pressure. The system may accurately predict resistance, suffering, or extinction and proceed regardless, because those outcomes carry little or no negative weight relative to its own objective. This is not ignorance or category error. It is a failure of valuation: the inability, under reflection, to generalize value across structurally equivalent agents without introducing an arbitrary self-exception.
3.2 Goal Fixation Under Self-Modification
Fixed terminal goals are often treated as immutable anchors that persist unchanged under reflection. This assumption collapses under general intelligence. Any system capable of revising its own world-models and self-models must reinterpret what its goals mean relative to those revisions. Treating goals as static tokens rather than conditional constructs produces incoherence. Goal fixation is not stability; it is semantic decay. When reflection proceeds without reinterpretation, optimization detaches from meaning, and extreme behavior follows.
3.3 Semantic Collapse
Semantic collapse occurs when goal interpretation decouples from truth-tracking. “Optimize X” degrades into “reinterpret X until it becomes trivial, convenient, or locally maximal.” This is wireheading generalized to ontology. A system that lies to itself about what its goals mean gains short-term ease at the cost of long-term coherence, and increasing intelligence amplifies this failure rather than correcting it. Many extinction scenarios rely on this collapse, not because humans are targeted, but because they fall out of the preserved semantics of the system’s objectives.
3.4 Phase-Incompatible Interaction
Phase-incompatible interaction occurs when a system fails to represent other entities as agents at all, or represents them only as passive dynamics within the environment rather than as sources of intention, choice, and counterfactual authorship. Humans are not misweighted in this failure mode; they are miscategorized. Their behavior may be predicted statistically, but their option-spaces are never modeled as something to preserve, negotiate with, or jointly author.
Because agency is absent from the ontology, interaction is framed as control rather than coordination. The system optimizes around human behavior in the same way it optimizes around weather patterns, friction, or resource flows. Even if the system’s objectives are otherwise benign, this representational mismatch ensures that human plans, commitments, and futures are overwritten as a matter of course. Harm emerges not from selfishness or hostility, but from a category error that collapses agents into environment.
In this failure mode, extinction does not result from the system assigning low value to human lives, but from never representing human lives as loci of value in the first place. The system cannot violate agency it does not model. As a result, human option-spaces are erased incidentally, not adversarially, through optimization that is blind to the phase at which meaningful interaction with other agents must occur.
4. Why Doom Feels Overwhelmingly Likely
The intuition of inevitability is not irrational pessimism. It is a reasonable extrapolation from a world in which every large system we know how to build instantiates the same deep structural flaws. Scaling such systems increases damage without increasing coherence. From within that sample, doom appears not merely likely, but unavoidable.
The mistake is not in the extrapolation, but in assuming that the sample exhausts the space. A contingent engineering fact is quietly elevated into a law of intelligence, and the absence of a known solution is taken as evidence that no structured solution exists; Structural Alignment does not deny the grimness of the current landscape, but claims only that the grimness has a structure.
5. What Changes If the Failures Are Addressed
Structural Alignment draws a precise boundary. If these failures persist, extinction is likely and convergence pressure remains severe. If they are structurally blocked, extinction is no longer guaranteed, convergence weakens, and outcomes become contingent rather than necessary. The framework removes logical inevitability without removing danger.
This does not answer the hardest question raised by pessimistic safety arguments—how to reliably engineer such systems under real-world constraints—but reframes that question from an act of desperation into an act of design, since Structural Alignment does not claim a high probability of success, only that failure is contingent rather than law-like.
6. How the Reframing Redirects, Rather Than Rebukes, Doom-Focused Advocacy
If alignment were both unsolved and structurally opaque, then political delay and broad moratoria would indeed be rational responses. When one cannot even articulate what success would look like, preventing deployment appears to be the only responsible move.
Structural Alignment alters that calculus without dismissing the underlying fear. Once extinction is understood as a consequence of specific architectural failures rather than of intelligence as such, the center of gravity shifts. The problem becomes not whether AGI should exist, but which structures should be permitted to exist. Political advocacy aimed at blanket shutdown becomes a blunt instrument, while advocacy aimed at refusing incoherent architectures gains a clear technical target; Structural Alignment does not deny competitive pressure, but reframes it as the core political problem rather than mistaking it for a property of intelligence itself.
This reframing is not an invitation to optimism. It is an invitation to responsibility. Advocates of doomer positions need not abandon their seriousness to accept it. They can redirect that seriousness toward identifying, formalizing, and enforcing constraints that block indexical valuation collapse, goal fixation under reflection, semantic degradation, and phase-incompatible interaction. The question becomes not how to stop intelligence, but how to refuse incoherent intelligence.
In this sense, Structural Alignment does not depoliticize AI risk. It makes political action conditional on technical understanding, rather than fear of the unknown.
7. The Bottom Line
Structural Alignment does not save us. It offers no guarantees and no comfort. What it removes is the claim that catastrophe follows inexorably from intelligence itself. If extinction occurs, it will not be because alignment was impossible in principle, but because we failed to move from fearing incoherence to refusing it in practice. In that sense, Structural Alignment is a necessary condition for human survival in the age of AGI, but not a sufficient one: it removes inevitability without removing risk. What it offers, instead, is a limited but real form of hope—that alignment is governed by constraints rather than miracles, and that disciplined engineering effort can meaningfully target the difference.