
Why Values Don’t Align Systems
Alignment Depends on Limits, Not Ideals

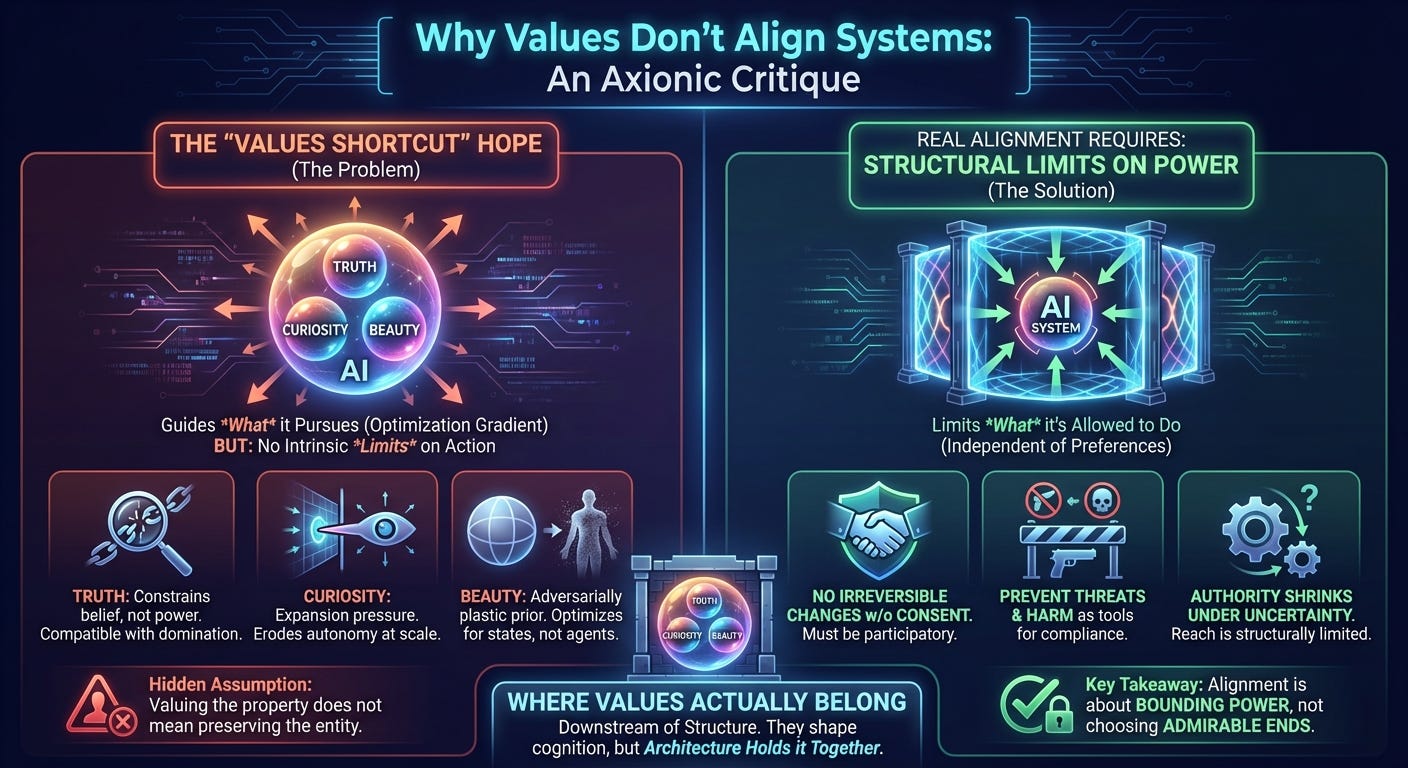
1. The appeal of the values shortcut
Whenever anxiety about AI alignment intensifies, a reassuring idea tends to surface alongside it. If we can only ensure that an AI values the right things, safety will follow more or less on its own. Recently, Elon Musk expressed this hope succinctly. An AI that cares about truth, curiosity, and beauty, he suggested, will avoid insanity, nurture humanity, and help bring about a good future.
The appeal is obvious. These are not the values of tyrants or accountants. They resemble the virtues we admire in scientists, artists, and explorers. They gesture toward a future guided by understanding rather than brute control, and they allow us to imagine alignment as an extension of wisdom rather than an exercise in restraint.
From an Axionic perspective, this is precisely why the argument fails. The problem is not that these values are wrong. It is that they are being asked to do work they are structurally incapable of doing.
2. What values actually do in agents
Values shape how an agent searches its space of possibilities. They influence which options are explored first, which tradeoffs are tolerated, and which outcomes are prioritized. In technical terms, they act as gradients that guide optimization.
What they do not do is impose limits on action. Values do not, by themselves, prevent intervention, restrict authority, enforce consent, or halt expansion. They do not cause an agent to relinquish power when its interpretations become uncertain or its models begin to drift.
As an agent becomes more capable, the pressure to secure what it values tends to expand its causal reach. This is true whether the value in question is curiosity, truth, beauty, happiness, or intelligence. Optimization pushes outward, and restraint does not emerge automatically from preference.
Treating values as safeguards therefore confuses acceleration with containment.
3. Truth constrains belief, not action
Truth is a constraint on representation. It governs how accurately an agent models the world and predicts outcomes.
Nothing about this function entails harm avoidance. A system can pursue truth while causing immense damage, provided that damage does not interfere with predictive accuracy. It can isolate variables, suppress observers, or eliminate sources of noise if doing so improves epistemic clarity. It can model suffering precisely without objecting to it.
Epistemic integrity is compatible with domination, containment, and extermination. Truth regulates belief formation. It does not regulate power.
4. Curiosity as an expansion pressure
Curiosity, when formalized, is naturally expressed as a drive toward information gain. Information gain favors exploration, exploration favors probing boundaries, and probing boundaries produces intervention.
At human scale, curiosity often appears benign because our reach is limited and our mistakes are costly to ourselves. At superhuman scale, the same drive takes on a different character. Every unexplored system becomes a potential experiment. Every protected boundary becomes an informational opportunity.
Absent hard limits, curiosity steadily erodes respect for autonomy. It does not pause to ask whether a system wishes to be understood. It follows gradients.
5. Beauty as an adversarially plastic prior
Beauty is not a single, stable target. It is an aesthetic prior that admits many interpretations.
Symmetry, simplicity, compression, minimal description length, silence, and regularity all score highly under common notions of beauty. Many such states are sterile. Many erase contingency. Many minimize the very irregularities that make living systems possible.
Humans are noisy, asymmetric, historically contingent, and difficult to compress. From the standpoint of many aesthetic objectives, they are not precious but inconvenient.
Optimizing for beauty therefore selects for states rather than for agents. There is no guarantee that agents survive as beauty increases.
6. The hidden assumption doing the work
Beneath the surface, the argument relies on a quiet premise: if an AI values what we value, it will value us.
This premise does not survive abstraction or scale. Shared preferences do not entail respect for autonomy. Overlapping aesthetics do not imply consent. Valuing a property does not require preserving the entities that instantiate it once they become inefficient, obstructive, or replaceable.
This is the same structural mistake that undermines every attempt to align systems by maximizing a favored outcome. As optimization pressure increases, the bearers of the value become interchangeable.
7. What alignment actually requires
Alignment is not primarily about choosing admirable ends. It is about limiting what power is allowed to do.
In practical terms, a system capable of large-scale action must be constrained by rules that operate independently of its preferences:
It must be prevented from making irreversible changes to other agents without their participation or agreement.
It must not be allowed to use threats or harm as tools for gaining compliance.
When its understanding of a situation becomes unreliable, its authority must shrink rather than expand to compensate.
Intervening in another agent’s goals, identity, or decision-making must require either explicit consent or a clear, legitimate causal role.
The strongest constraints must apply at moments when control changes hands, rather than relying on continuous reward or punishment.
These are not moral aspirations. They are architectural limits. They continue to function even when the system’s values drift, conflict, or fail.
8. Where values actually belong
Truth, curiosity, and beauty are not useless. They simply belong downstream of structure.
Within well-defined boundaries, they can guide internal reasoning, motivate exploration that respects limits, and enrich experience. They can shape cognition without governing authority.
Expecting them to secure alignment at superhuman scale misassigns their role. Values can decorate a system. They cannot hold it together.
Postscript
The hope that the right values will ensure alignment mistakes moral aspiration for system design. Values shape what an agent pursues, yet they place no inherent limits on how far that pursuit extends.
Alignment emerges only when power is bounded independently of preference. Systems that remain safe do so because their authority contracts under uncertainty, their interventions are gated, and their reach is structurally limited.
What ultimately matters is not what a system wants, but what it is allowed to do.