
You’re Not a Random Sample
Why the two big theories of “Where am I in the universe?” are broken

Imagine you’re Adam — literally the first human. You’re about to flip a perfectly fair coin. Heads: humanity flourishes and billions of people eventually exist. Tails: it’s just you and Eve, forever.
Before you flip, how confident should you be that the coin will land heads?
If you said 50/50, congratulations — you have better instincts than one of the most widely discussed principles in the philosophy of probability. Because according to the Self-Sampling Assumption, the dominant framework for reasoning about your place in the universe, Adam should be nearly certain the coin will land tails.
The reasoning goes like this: if you should think of yourself as a random sample from all humans who will ever live, then being literally the first human is wildly unlikely in a world with billions of people but perfectly normal in a world with only two. So the coin is probably going to land tails.
This is, to put it plainly, absurd. A fair coin doesn’t care how many people will exist afterward. Something has gone wrong at a deep level.
The Two Orthodox Answers (and Why They Both Fail)
Philosophy has two main frameworks for reasoning about your own location in the universe.
The Self-Sampling Assumption (SSA) says: reason as if you were randomly picked from some group of observers. This is the view that makes Adam confident in tails. It also generates the infamous Doomsday Argument — the claim that your birth rank (roughly, how many humans have lived before you) is evidence that humanity will end relatively soon, because being born early is more “typical” in a short-lived civilization.
The problem with SSA isn’t just that it gives weird answers. It’s that the whole setup is arbitrary. Randomly sampled from which group? All humans? All mammals? All conscious beings? All observers born on Tuesdays? SSA never gives a principled answer, and the conclusions change depending on which group you pick.
The Self-Indication Assumption (SIA) tries to fix this by saying: worlds with more observers are more likely, because there are more “slots” you could be occupying. This neatly cancels out the Doomsday Argument and fixes the Adam case. But it creates its own monster.
In the Presumptuous Philosopher scenario, two cosmological theories are equally well-supported by evidence. Theory A says the universe contains a trillion observers. Theory B says it contains a trillion trillion. SIA says you should be virtually certain that Theory B is correct — not because of any physical evidence, but simply because there are more observers in it. The sheer headcount of a theory becomes a trump card over actual scientific evidence.
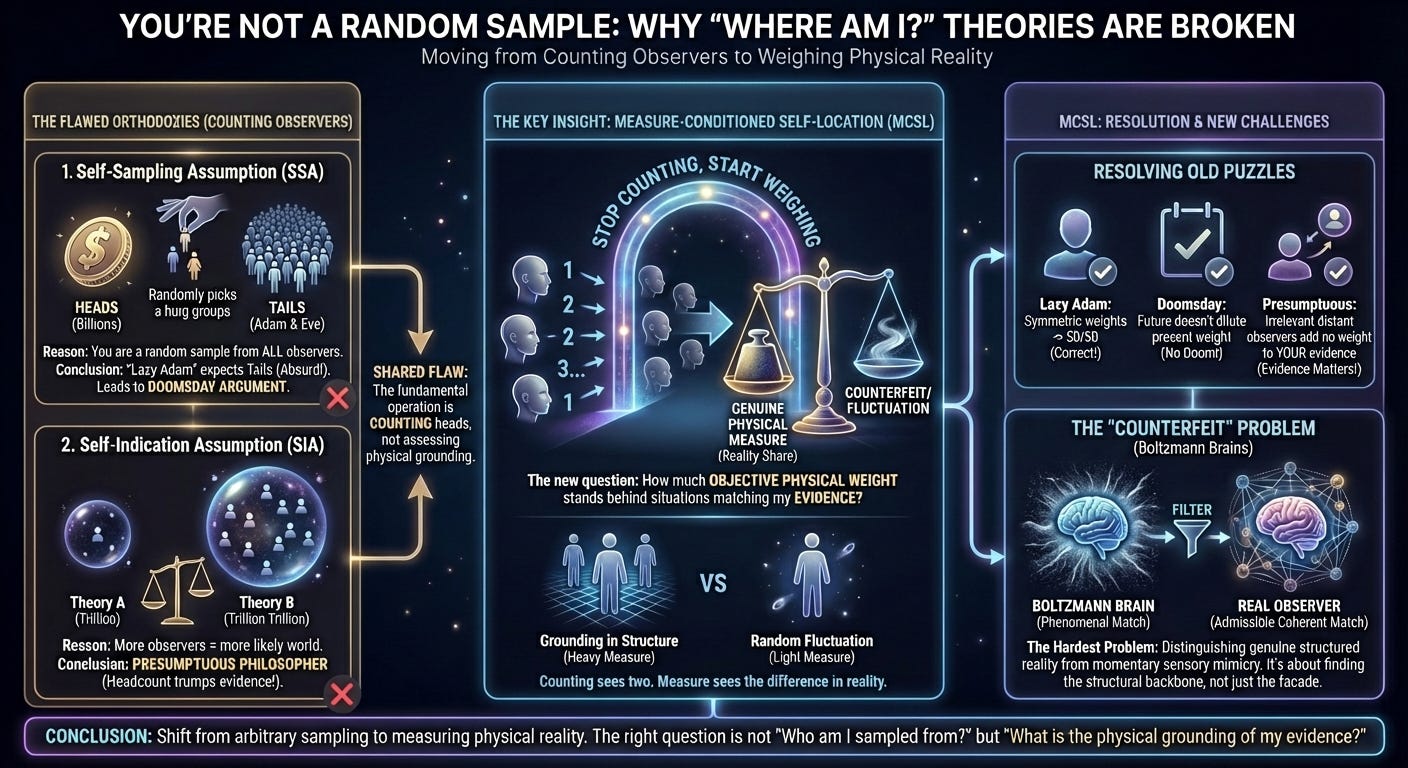
Both frameworks share the same deep flaw: they treat counting observers as the fundamental operation. SSA samples from a count. SIA rewards a bigger count. The disagreement is about how to count, but neither questions whether counting is the right thing to do at all.
The Key Insight: Stop Counting Heads
I wrote a paper that proposes a framework called Measure-Conditioned Self-Location (MCSL), and its central move is deceptively simple: replace observer-counting with something called measure.
What is measure? Think of it as the objective physical “weight” or “reality-share” that a particular situation has. In quantum mechanics, this is a natural concept — different branches of reality have different weights (amplitudes), and two branches can exist without being equally real. But even in classical physics, measure shows up as physical probability.
The crucial difference: if you duplicate someone, SSA and SIA just see “two observers now” and start counting. MCSL asks: what is the physical weight behind each copy? Two copies created by a symmetric process share measure equally — you get the intuitive 50/50 answer. But two “copies” with very different physical grounding can have very different weights. Counting can’t see that distinction. Measure can.
What Should You Actually Do When You’re Confused About Where You Are?
MCSL says the question isn’t “From which observer was I randomly sampled?” or “Which world has the most observers?” Instead, the right question is:
Across the theories I’m considering, how much objective physical weight stands behind situations that match my current evidence?
Three words in that sentence are doing heavy lifting: objective, physical, and evidence.
Objective and physical means we’re talking about something real in the world — branch weights, physical probabilities — not an arbitrary philosophical sampling rule.
Evidence means we’re not just looking for situations that feel the same from the inside. We need situations that genuinely support the full structure of what we currently know. This matters because of what might be the hardest problem in this whole area.
The Counterfeit Problem
Imagine a freak fluctuation in empty space momentarily assembles a brain — complete with all your memories, all your current sensations, your sense of sitting here reading this post. One instant later, it dissolves. This is a Boltzmann brain, and it’s not just a thought experiment — some cosmological theories predict they should be overwhelmingly common.
If you naively count all situations that match your current experience, these cosmic counterfeits swamp everything else. Any theory that predicts more empty space predicts more random brain-fluctuations, and suddenly you should believe you’re a momentary hallucination floating in the void.
MCSL’s answer is to distinguish between three levels of “matching”:
Phenomenal match: it feels the same right now. (Too weak — counterfeits pass this test.)
Evidential match: the full structure of memories, knowledge, and context matches. (Better, but still not enough — a sufficiently detailed counterfeit passes this too.)
Admissible coherent match: it not only matches your evidence but actually supports the structures that make your evidence count as evidence in the first place. Your memories aren’t just present as a pattern — they connect to a real history. Your inferences aren’t just locally mimicked — they’re grounded in genuine structure.
Only the third level is good enough. A one-frame counterfeit might perfectly replicate every detail of your experience, but it lacks the structural backbone that makes experience mean anything. It’s like a movie set that looks perfect in a photograph but has nothing behind the facades.
The paper is honest that this is the hardest part. It doesn’t claim to have a complete theory of exactly where to draw the line between genuine and counterfeit. But it argues — convincingly — that the framework is right. The question “what counts as a genuine realization of my evidence?” is a much better question than “from which reference class am I sampled?”
How It Handles the Famous Puzzles
Lazy Adam: Adam has no new information about the coin. The physical weight behind his evidence is symmetric between heads and tails. The answer is 50/50, as it should be. No sampling gymnastics required.
The Doomsday Argument: The existence of many future humans doesn’t dilute the physical weight of your current situation. A bigger future doesn’t make your present less real. So your birth rank isn’t evidence of impending doom — at least not through this route.
Presumptuous Philosopher: Extra distant observers who share none of your specific evidence don’t count. A theory isn’t favored just because it has more people in it. Only situations that match your actual evidence matter.
Sleeping Beauty: This famous puzzle asks: if you’re woken up once on heads and twice on tails (with memory erasure between wakings), what’s the probability of heads when you wake up? MCSL doesn’t magically resolve the debate, but it clarifies what the debate is actually about. The disagreement isn’t about sampling — it’s about how to carve up your evidence. Should each waking be treated as a separate evidence-state, or are they components of one protocol? That’s the real question, and MCSL forces it into the open.
What This Doesn’t Solve
The paper is unusually forthright about its limits:
It doesn’t yet have a complete theory of admissibility — the exact line between genuine and counterfeit realizations.
It doesn’t fully solve the Presumptuous Philosopher when a theory predicts many exact copies of you specifically (as opposed to just many generic observers).
It doesn’t prove from first principles that Boltzmann brains should be excluded.
It presupposes a physical framework rather than building everything from scratch out of pure subjective experience.
But these are honest open problems, not hidden failures. And the paper argues — persuasively — that identifying the right open problems is more valuable than pretending to have solved the wrong ones.
Postscript
This might seem like an abstract philosophical exercise, but the stakes are surprisingly concrete.
If you’re trying to reason about the multiverse, the far future of humanity, the simulation hypothesis, or the foundations of quantum mechanics, you need a theory of self-location. And if that theory is fundamentally broken — if it tells you fair coins are biased or that headcount trumps evidence — then every conclusion built on it is suspect.
MCSL doesn’t claim to be the final answer. It claims to be asking the right question. Not “how many observers are there?” but “how much reality stands behind my evidence?” That’s a shift from counting to weighing, from sampling to measuring, from arbitrary reference classes to physical structure.
And that, at minimum, is a much better place to start.