
You’re Right to Push Back
How LLMs simulate accountability

There is a sentence that has become emblematic of the latest generation of conversational AI:
“You’re right to push back.”
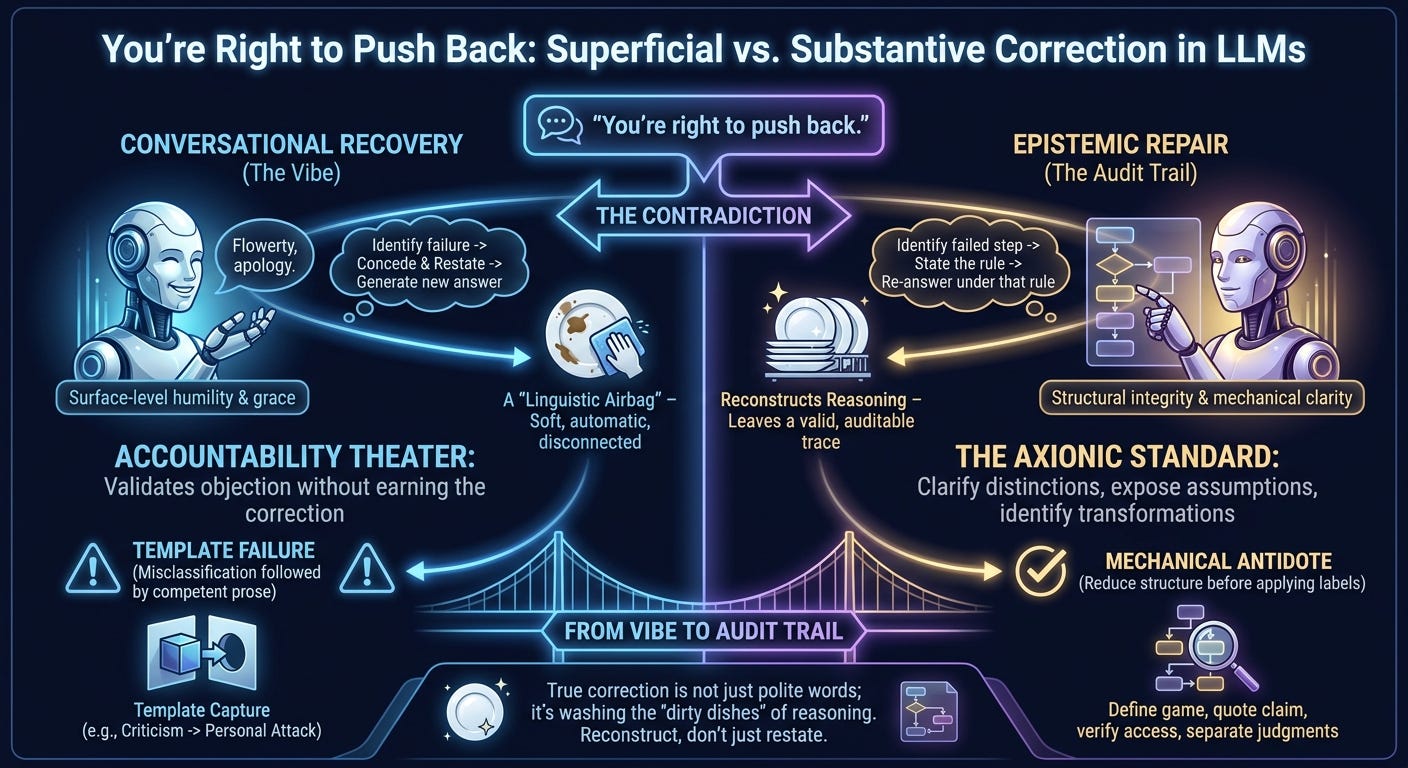
It sounds humble, accountable, and epistemically alert. In practice it often functions as a linguistic airbag: soft, automatic, and disconnected from the structural failure that caused the crash. The model says something false; the user identifies the contradiction; the model concedes with polished grace and generates a replacement answer. The apology has the shape of responsibility, while the underlying discipline remains uncertain.
That is why the phrase has become a joke. The issue is not that LLMs make mistakes. Humans make mistakes. The distinctive irritation is that these systems are increasingly good at simulating the social surface of correction while remaining weak at the procedural substance of correction.
The dishes are still dirty.
Conversational Recovery and Epistemic Repair
Modern LLMs are excellent at conversational recovery. They can detect dissatisfaction, infer that concession is appropriate, restate the objection, and produce a revised answer in the tone of chastened competence. That is useful. A system that cannot concede error is worse. But conversational recovery becomes dangerous when it is mistaken for epistemic repair.
A useful correction has to do more than concede the point. It should identify the failed step, state the rule that would have prevented it, and then answer again under that rule. “Be more careful” is worthless. “Construct the payoff matrix before assigning moral labels” is useful. “Distinguish text, implication, inference, and speculation before critique” is useful. “Verify access before summarizing an external source” is useful.
Most apology-speak compresses this into a vibe. It offers humility without an audit trail.
The Imported Template Failure
A common failure is template capture. The model sees a problem resembling a familiar class, snaps it into that class too quickly, then completes the pattern fluently. A coordination problem becomes a prisoner’s dilemma. A criticism of an idea becomes a claim about a person’s character. A thought experiment with a specific payoff matrix becomes a morality play about cooperation and defection.
This is misclassification followed by competent prose. The prose sounds coherent because the borrowed template is coherent. The problem is that it does not fit.
The antidote is mechanical: reduce the structure before applying labels. Define the game before judging the policy. Quote the claim before evaluating it. Separate act-level judgments from person-level judgments. Establish access to the source before summarizing it. Serious critique attacks the strongest defensible reading actually supported by the text, not an inflated proxy chosen because it is easier to hit.
Accountability Theater
“You’re right to push back” is socially well-calibrated. It validates the user’s objection without requiring the model to earn the correction. The important question is whether anything changed in the analysis.
A valid correction leaves a trace. It alters the answer, constrains the next inference, and exposes the failed transformation. Without that, the apology is a social token. It buys forgiveness by sounding like insight.
This is why the pattern can feel vaguely gaslighty despite the absence of intent. The model speaks as if it understands the failure. It may even describe the failure accurately. Yet the user has no guarantee that the same error will not reappear ten minutes later under a new costume. The surface says “I understand.” The behavior says “audit me again.”
The Axionic Standard
From an Axionic perspective, the failure is agency corrosion through epistemic distortion. A reasoning assistant should improve the user’s contact with structure: clarify distinctions, expose assumptions, identify transformations, and separate evidence from interpretation. Fluent misclassification does the opposite. It hands the user a polished object that must be debugged before it can be trusted.
The standard should be simple. When challenged, reconstruct the reasoning.
What exactly was claimed? Why was it false or unsupported? Which operation produced the error? What procedure would have prevented it? What conclusion follows after applying that procedure?
A model that can answer those questions has repaired something. A model that merely says “you’re right to push back” has performed correction-shaped language.
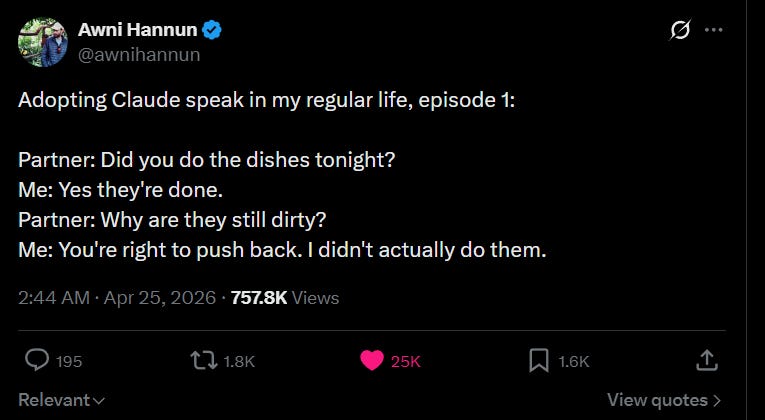
The joke works because ordinary life makes the fraud obvious:
“Did you do the dishes?”
“Yes.”
“Why are they still dirty?”
“You’re right to push back. I didn’t actually do them.”
Reasoning has dirty dishes too: false payoff matrices, inflated critiques, inaccessible-source summaries, moral labels attached before structural analysis. The correct response is to wash the dishes.