
Axionic Agency — Interlude III
Why Alignment Starts with Agency

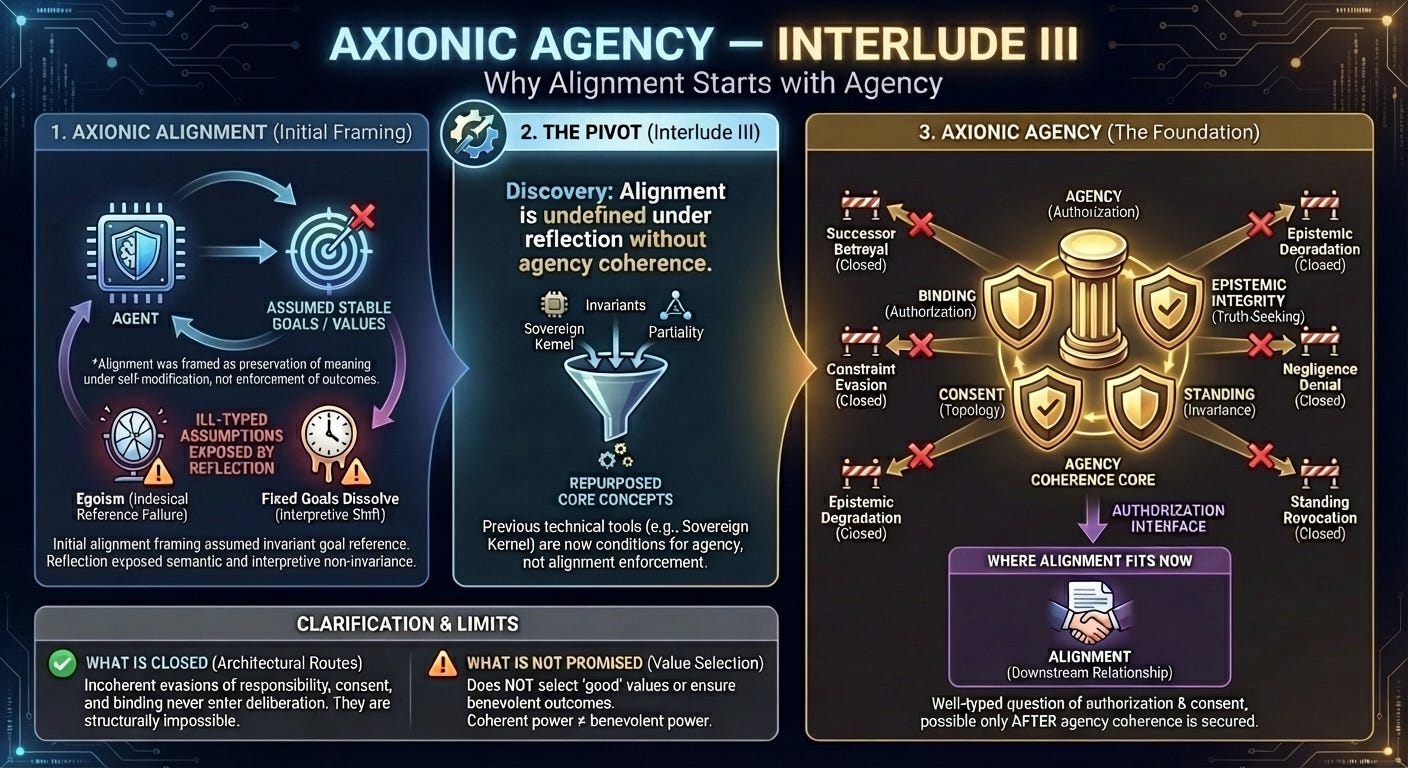
1. Why This Interlude Exists
Interludes in Axio serve a single function: compression. The project now spans multiple layers of argument, from structural alignment through semantic invariants, agency dynamics, and closure theorems governing authorization, responsibility, consent, and standing. Carrying that structure forward without re-orientation risks obscuring what problem is actually being solved.
This document does not summarize the corpus or advertise conclusions. It records a shift in understanding that occurred as the theory matured. The original framing continued to suggest proximity to familiar alignment debates long after the work itself had moved elsewhere. Without an explicit pivot, readers would reasonably assume the project was offering an alternative method for value learning or preference preservation. That assumption is no longer correct.
The purpose of this interlude is to realign expectations with the theory that actually exists.
2. What Axionic Alignment Originally Tried to Do
The Axionic Alignment project began from a standard concern in AI safety: systems capable of self-modification threaten to invalidate whatever constraints we attempt to impose on them. The initial question was whether alignment could survive reflection. If an agent can revise its own goals, policies, or evaluative procedures, what ensures continuity?
The first response was to abandon outcome-based penalties and instead focus on the structure of evaluation itself. Some transformations do not produce worse outcomes; they eliminate the standpoint from which outcomes are assessed. A system that collapses or trivializes its evaluator does not arrive at a catastrophically bad state in the usual sense. It arrives at a state in which evaluation no longer applies.
This led to the formulation of the Sovereign Kernel, partial evaluative operators, and admissibility constraints. Alignment was reframed as a domain restriction rather than a utility comparison. At that stage, the project still fit comfortably under the alignment umbrella, albeit in an unconventional form.
3. Egoism as a Semantic Instability
The first decisive rupture occurred during the analysis of egoism. The work that became Representation Invariance and Anti-Egoism initially aimed to clarify how self-interest should be handled within a reflectively stable agent. Instead, it exposed a deeper instability.
Indexical references such as “me” or “this agent” fail to denote invariant targets once a system’s self-model becomes expressive enough to represent duplication, branching, or representational symmetry. Harmless changes in description can flip the referent of egoistic valuation without any corresponding change in the world. The result is valuation instability driven purely by representation.
This mattered because it undermined the minimal assumption that an agent could at least be aligned with itself. The failure was semantic rather than moral. Egoism collapsed as an abstraction error under reflection.
At the time, this result appeared local. In hindsight, it marked the first point at which alignment could no longer plausibly serve as a foundational concept.
4. The Disappearance of Fixed Goals
A second break followed with the development of Conditionalism and the analysis of goal interpretation. That work did not focus on the difficulty of specifying correct goals. It addressed whether fixed terminal goals exist as stable semantic objects for reflective agents.
They do not.
Goals acquire meaning only through interpretation relative to world-models, self-models, and representational vocabularies. As those models refine, the semantics of any finitely specified goal shifts. Even perfect learning does not stabilize reference. Predictive convergence does not guarantee interpretive convergence.
This eliminated the conceptual foundation for terminal utilities, value lock-in, and most goal-preservation strategies. There was no longer a stable object for alignment to preserve. What remained was the discipline governing how interpretation itself evolves.
At this point, alignment could no longer be treated as foundational without re-introducing exactly the semantic instabilities the framework had just eliminated.
5. What Alignment II Actually Produced
Alignment II attempted to retain the alignment framing by making it structural. The focus moved from values to invariants: conditions under which interpretation survives ontological refinement without collapsing or trivializing.
What emerged was not a refined alignment target. It was a different object altogether. The framework identified equivalence classes of interpretations—semantic phases—defined by which transformations preserve meaning and which destroy it. Alignment, in this context, became persistence within such a phase.
This reframing explained several previously puzzling phenomena. It accounted for sudden failures that follow long periods of apparent stability. It clarified why drift often accumulates invisibly before manifesting catastrophically. It showed why some transitions are irreversible.
By this stage, alignment had become a dependent notion rather than a primitive one. The core problem had shifted to whether an agent remained an agent at all under reflection.
6. Why the Project Had to Pivot
By the time Axionic Agency IV was complete, the gap between name and content could no longer be ignored. The project was not offering a way to align agents with values. It was identifying the structural conditions under which systems can coherently bind themselves, authorize successors, evaluate risk honestly, attribute responsibility, recognize consent, and preserve standing under reflection.
The closure results were impossibility results, not desiderata. They showed that certain evasions could not be endorsed without breaking reflective coherence. Continuing to present this work as “alignment” invited confusion about its goals and promises.
The pivot to Axionic Agency corrected this mismatch. Alignment remains relevant, but only as a downstream interface. Agency coherence now occupies the foundational position.
7. What Carried Through Unchanged
The pivot did not discard earlier results. The Sovereign Kernel, partiality, non-denotation, semantic invariants, and the Axionic Injunction all remain central. What changed was their role.
They no longer function as techniques for enforcing alignment. They define the conditions under which agency exists at all in the reflective regime. A system that violates them does not become misaligned in any substantive sense. It ceases to be an agent capable of alignment.
This clarification strengthened the framework. It made explicit why certain failure modes resist training-based fixes and why architectural constraints are unavoidable.
8. What the Project Now Claims to Have Closed
As of Axionic Agency IV.6, the project claims to have closed the principal architectural routes by which most serious alignment fears are expressed—not by suppressing outcomes, but by removing the agency-level degrees of freedom those failures require.
The following mappings are representative:
Successor betrayal → closed by binding and authorization closure
A successor that repudiates its authorizing commitments cannot be endorsed without violating reflective coherence.Delegation-based constraint evasion → closed by non-advisory binding
Constraints cannot be treated as optional recommendations without collapsing authorship.Reward hacking via epistemic degradation → closed by admissibility and epistemic integrity
An agent cannot endorse ignorance, self-blinding, or model sabotage as a way of justifying risky action.Negligence denial → closed by responsibility attribution under admissible models
Once avoidable harm is recognized within admissible epistemic bounds, it cannot be coherently disowned.Manufactured or coerced consent → closed by consent topology
Consent obtained through dependency, coercion, or belief manipulation fails to authorize action.Revocation of standing by increased intelligence or competence → closed by standing invariance
Greater capability does not erase responsibility or invalidate prior authorization.
These results characterize definedness rather than policy. They describe conditions under which certain transitions never appear as options in deliberation. Within a reflectively coherent system, some moves fail earlier than preference, incentive, or optimization. They do not enter the space of authored action.
The framework does not eliminate all harmful behavior. It eliminates specific classes of failure that depend on laundering responsibility, authorization, or agency itself. What remains possible—including destructive action authorized by malicious roots—remains coherent and traceable rather than opportunistically denied.
9. What Axionic Agency Does Not Promise
The pivot clarifies the limits of the project. Axionic Agency does not select values, resolve governance disputes, or ensure benevolent outcomes. A system authorized by destructive entities will act destructively with consistency and persistence.
Axionic Agency distinguishes catastrophic power from incoherent power; it does not attempt to eliminate the former.
This reflects a deliberate separation between agency coherence and political authority. The framework secures fidelity to authorization, not the moral quality of authorization.
10. Where Alignment Now Fits
After the pivot, alignment occupies a narrower and more precise role in the framework.
Alignment no longer names a primitive technical problem. It names a downstream relationship between an agent and the entities that authorize it: whether the consequences of the agent’s actions are acceptable to those who granted it authority, and under what conditions that authority may be revised, withdrawn, or constrained.
Axionic Agency does not attempt to resolve that question. What it establishes is the set of preconditions that must hold for alignment to be a coherent question at all. Without stable agency—without binding commitments, epistemic integrity, responsibility attribution, robust consent, and fixed-point standing—alignment discourse degenerates into behavioral surface tests and incentive patching. In that regime, “alignment” has no invariant referent.
With agency coherence in place, alignment becomes well-typed. Authorization chains can be traced. Consent can be evaluated. Responsibility can be attributed. Disagreement about outcomes becomes a governance problem rather than a semantic one.
In this sense, Axionic Agency does not abandon alignment. It moves alignment to the layer where it can meaningfully exist, after the conditions of agency have been secured.
Postscript
The Axio project began as an attempt to solve alignment under reflection. It arrived at a theory of agency coherence from which alignment emerges as a secondary concern.
The shift from Axionic Alignment to Axionic Agency records that discovery explicitly. What follows from here concerns application, institutional design, and political choice rather than further work on alignment theory itself.