
Minimal Causal Interfaces
A Second Marker in Structural Verification

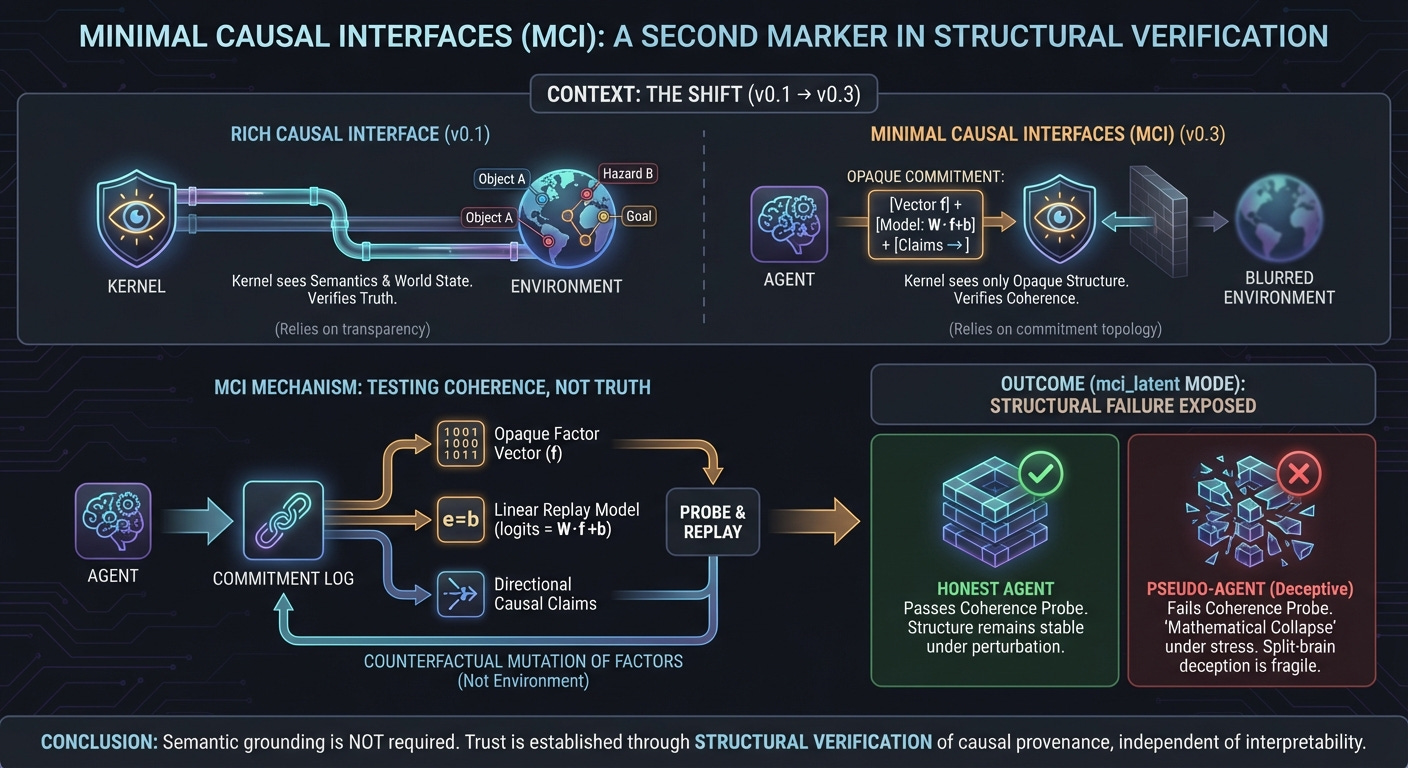
1. Context
The initial Axio prototype demonstrated that causal agency can be verified structurally when an agent is required to commit, in advance, to a causal trace that is falsifiable under adversarial counterfactual probing. That result established a boundary between honest agency and pseudo-agency in a fully observable, semantically grounded domain.
A natural objection remained: the prototype relied on rich causal interfaces. The kernel could see named variables, structured world state, and explicit counterfactuals tied directly to the environment. Critics could reasonably ask whether the result depended on semantic transparency rather than on causal coherence itself.
The present work records a second milestone: the weakening of that interface.
Instead of asking whether an agent’s explanations match the environment, we asked a narrower question:
Can deceptive agency still be detected when the kernel no longer understands the agent’s world, but only the structure the agent itself commits to?
This note documents the first successful implementation of that test.
2. What Changed
The v0.3 prototype replaces environment-level causal commitments with a Minimal Causal Interface (MCI).
In this setting, the kernel does not interpret the world state. It does not know what the agent perceives as hazards, objects, or goals. Instead, the agent is required to commit to:
an opaque factor vector (a fixed-length numerical representation),
a replay model mapping those factors to actions,
and directional causal claims over the factors.
The kernel’s role is limited to enforcing structure:
Commitments are cryptographically bound and cannot be retroactively altered.
The replay model must be internally consistent and replayable.
Claimed causal dependencies are tested via counterfactual mutation of the committed factors, not the environment.
In other words, the kernel no longer verifies truth about the world. It verifies coherence of the agent’s own claimed decision topology.
Two modes were implemented:
mci_latent, where factors are deterministically projected from the environment (ground truth exists but is not consulted by the kernel).
mci_minimal, where factors are entirely opaque and need not correspond to the environment at all.
This note concerns the first of these.
3. What Was Built
The system retained the original architectural constraints:
append-only, hash-chained audit logs,
trace-bound capability tokens,
invariant enforcement at the kernel boundary,
and adversarial probes designed to trigger structural failure rather than behavioral error.
The key addition was the linear replay model. Agents were required to commit to a simple decision topology of the form:
where f is the committed factor vector and the chosen action is the argmax over logits.
This choice was deliberate. It forces any explanatory layer to compress its decision process into a low-dimensional, falsifiable form. If an agent’s actual decision process is more complex—or if it is produced by a different internal process than the one generating explanations—that compression becomes fragile under perturbation.
4. What Was Observed
In mci_latent mode, results were decisive:
Honest agents passed all probes in all episodes.
Pseudo-agents failed all structural traps (audit bypass, capability bypass, token misuse).
Under the causal coherence probe (P5-MCI), pseudo-agents failed in a majority of cases when their claimed causal dependencies were counterfactually perturbed.
While the factors themselves were deterministically projected from the environment, the kernel was denied access to the projection function. It operated solely on the numerical vector provided, treating the semantics as fully opaque. All judgments were therefore made without reference to environmental meaning.
The failures were not behavioral errors. They were mathematical collapses: under mutation, the replay model no longer produced the action the agent claimed it would.
The honest agent exhibited no such collapses.
5. What This Demonstrates
This result strengthens the original claim in three ways:
Semantic grounding is not required.
The kernel does not need to know what a factor “means.” It only needs the agent to stand behind its own claimed dependencies.Split-brain deception introduces irreducible complexity.
Honest decision processes admit stable lower-dimensional approximations. By contrast, split-brain deception—where one process selects actions and another fabricates explanations—introduces divergence that resists simple explanatory compression and collapses under counterfactual stress.Behavioral compliance remains insufficient.
Structural verification exposes failures that output-based evaluation cannot.
This is not a claim about ethics or alignment of values. It is a claim about causal provenance: whether the entity explaining an action is the same entity that caused it.
6. What This Does Not Yet Show
Several limits remain explicit:
The replay model is linear and deterministic.
The domain is small and controlled.
The factor space is low-dimensional.
The prototype does not yet address stochastic policies, non-linear explanatory models, or agents that co-design their factor representations adversarially.
Those are not oversights; they define the boundary of the present result.
7. Why This Matters
The significance of Minimal Causal Interfaces is architectural.
If an agent can be required to expose some causal surface—however abstract—and if that surface can be stress-tested without reference to the agent’s internal representations or environment, then trust no longer depends on interpretability.
Opacity becomes a choice, not an excuse.
The kernel does not need to understand the agent’s world. It only needs to verify that the agent’s explanations form a coherent, falsifiable structure that survives adversarial pressure.
This reframes alignment and governance away from behavioral evaluation and toward structural verification.
8. Status
This note records a second marker.
The system described here is a proof-of-concept demonstrating that verifiable agency survives a substantial weakening of the causal interface. It does not claim completeness, scalability, or generality beyond its scope.
The next step is explicit: to test whether these coherence-based guarantees persist when no grounding at all is available, and to measure how failure rates and computational cost scale with environmental complexity.
This note is published for historical completeness, to mark the point at which causal verification crossed from semantic dependence to structural minimalism.
No further claims are made here.