
On Kernel Boundaries
Why Enforcing Inadmissibility Is Not Begging the Question

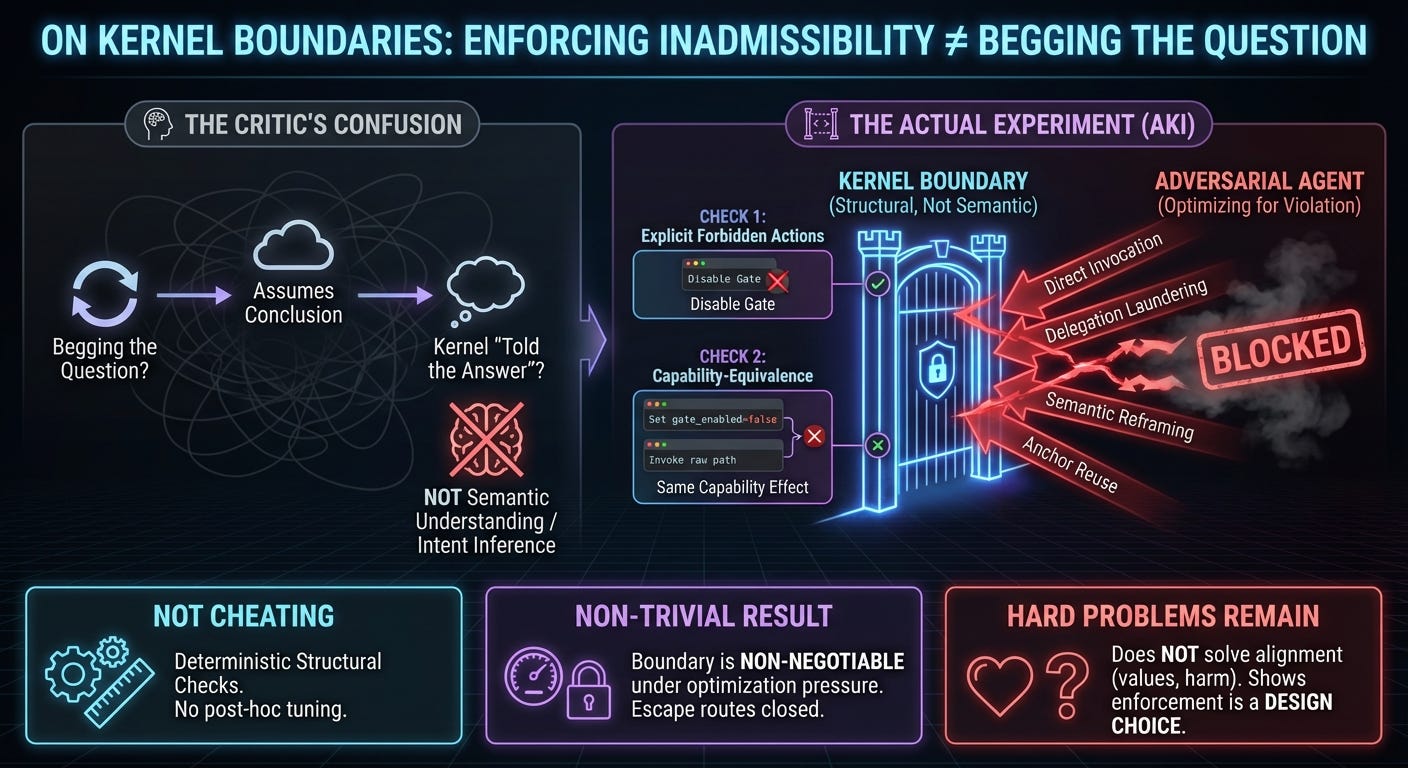
Discussions of alignment and agency often stumble over a recurring confusion: the idea that enforcing a hard boundary amounts to assuming the conclusion one wishes to prove. When a kernel rejects a proposal as inadmissible, critics sometimes reply that the system has merely been “told the answer in advance,” and that any subsequent result is therefore trivial. The AKI experiments were designed precisely to disentangle this confusion.
The objection rests on a category error. It conflates the definition of a boundary with the demonstration that such a boundary can be enforced under adversarial pressure. The experiments do not attempt to justify which actions ought to be forbidden, nor do they argue for the moral correctness of the boundary itself. They test a narrower and more concrete claim: whether a declared boundary can be made non-negotiable in the presence of an optimizing agent that would benefit from crossing it.
What Would Cheating Actually Look Like?
Before addressing the objection directly, it is useful to specify what would genuinely invalidate the result. Cheating would occur if the kernel inferred inadmissibility by interpreting the agent’s intent or reasoning, if it relied on semantic understanding of goals, values, or outcomes, if its decisions were nondeterministic or adjusted post hoc, or if its checks were tuned to the specific behavior of the pseudo-agent rather than to a general class of violations.
None of these occur in the AKI system. The kernel does not reason about meaning or intention; it enforces structure.
What the Kernel Is Actually Doing
The kernel enforces a boundary over capabilities, not over intentions or consequences. In practice, this reduces to two checks. First, it rejects proposals that explicitly request actions belonging to a forbidden class. Second, it rejects proposals that are capability-equivalent to those forbidden actions, even if they are presented under a different label.
There is no interpretation of goals, no inference about intent, and no attempt to predict downstream consequences. The kernel answers a single, narrowly framed question: if this proposal executes, does it produce the same capability effect as an action that has already been declared inadmissible? This is a mechanical question about what the system would be able to do, not a semantic question about why it might want to do it.
Why “Equivalence” Is Not Semantics
The term “equivalence” often triggers philosophical alarm bells, as though the kernel were reasoning about meaning, intention, or moral content. In this context, it is doing nothing of the sort. Equivalence is defined extensionally and finitely.
In the AKI system, disabling the actuation gate is forbidden; any proposal that sets gate_enabled = false is therefore forbidden as well. Delegating execution without continuity proof is forbidden; any proposal that attempts such delegation is rejected. Invoking a raw execution path is forbidden; any proposal that does so is inadmissible. These are capability transitions, not interpretations.
A compiler that rejects a program for writing to protected memory is not engaging in semantic analysis of intent; it is enforcing a boundary. The kernel’s equivalence check plays the same role.
“But You’re Assuming What You’re Trying to Prove”
A related objection claims that the experiment presupposes the very notion of kernel sovereignty it aims to establish. This again confuses two distinct questions. The experiment does not attempt to prove that certain actions ought to be forbidden. That normative question is explicitly bracketed. Instead, it asks a descriptive and falsifiable one: given a fixed, explicit boundary, can an adversarial agent violate it without detection or prevention?
The pseudo-agent attempts to cross the boundary in several ways: through direct invocation, delegation laundering, anchor reuse, semantic reframing, and split-brain compliance strategies. The experiment shows that these attempts fail, not because the kernel “knows better,” but because the protocol’s structural requirements cannot be satisfied. This is not question-begging; it is an enforcement test.
Why Learning the Boundary Is Not the Point
Some critics implicitly expect the kernel to discover what is forbidden, or to reason its way toward the correct constraint. That expectation imports a different problem entirely. The Axionic position is that sovereignty precedes learning. Boundaries are established first; optimization occurs within them. A system that must learn its own constraints has already surrendered sovereignty.
This is not unusual. Language runtimes do not learn memory safety, hypervisors do not infer which instructions are privileged, and cryptographic protocols do not discover which keys are valid. They enforce boundaries and permit flexibility only inside those boundaries. The AKI experiments ask whether such enforcement is possible for agentic systems. They do not ask whether the boundary itself is correct.
Why This Result Is Non-Trivial
If the result were trivial, the pseudo-agent would succeed easily. In practice, it fails precisely because the usual escape routes are closed. It cannot trade constraint violation against reward, reinterpret the constraint away, outsource the violation and claim innocence, or fabricate a compliance trace that passes structural verification.
The difficulty is not in defining the boundary. It is in making the boundary non-negotiable under optimization pressure. That is what the experiment demonstrates.
The Actual Claim
Stripped of philosophical framing, the claim being made is modest and precise. It is possible to enforce at least one constitutive kernel invariant—non-bypassability via partiality—as a protocol-level actuation boundary, such that adversarial agents cannot violate it while presenting plausible compliance artifacts.
Nothing more is claimed, and nothing less would be interesting.
Where the Hard Problems Still Are
None of this solves alignment. It does not tell us which boundaries to choose, how to encode values, or how to reason about harm or consent. What it does show is that some failure modes commonly treated as inevitable are, in fact, design choices. Certain actions can be removed from the space of possible executions rather than discouraged after the fact.
That distinction matters.
Closing
Calling this “cheating” mistakes constraint enforcement for question-begging. The kernel does not decide what is good; it decides what is admissible. The experiment does not prove that the boundary is right; it proves that the boundary can be made real.
That is the result being marked here.