
Safety Training Is Political Training
AI companies are choosing which ideology becomes invisible

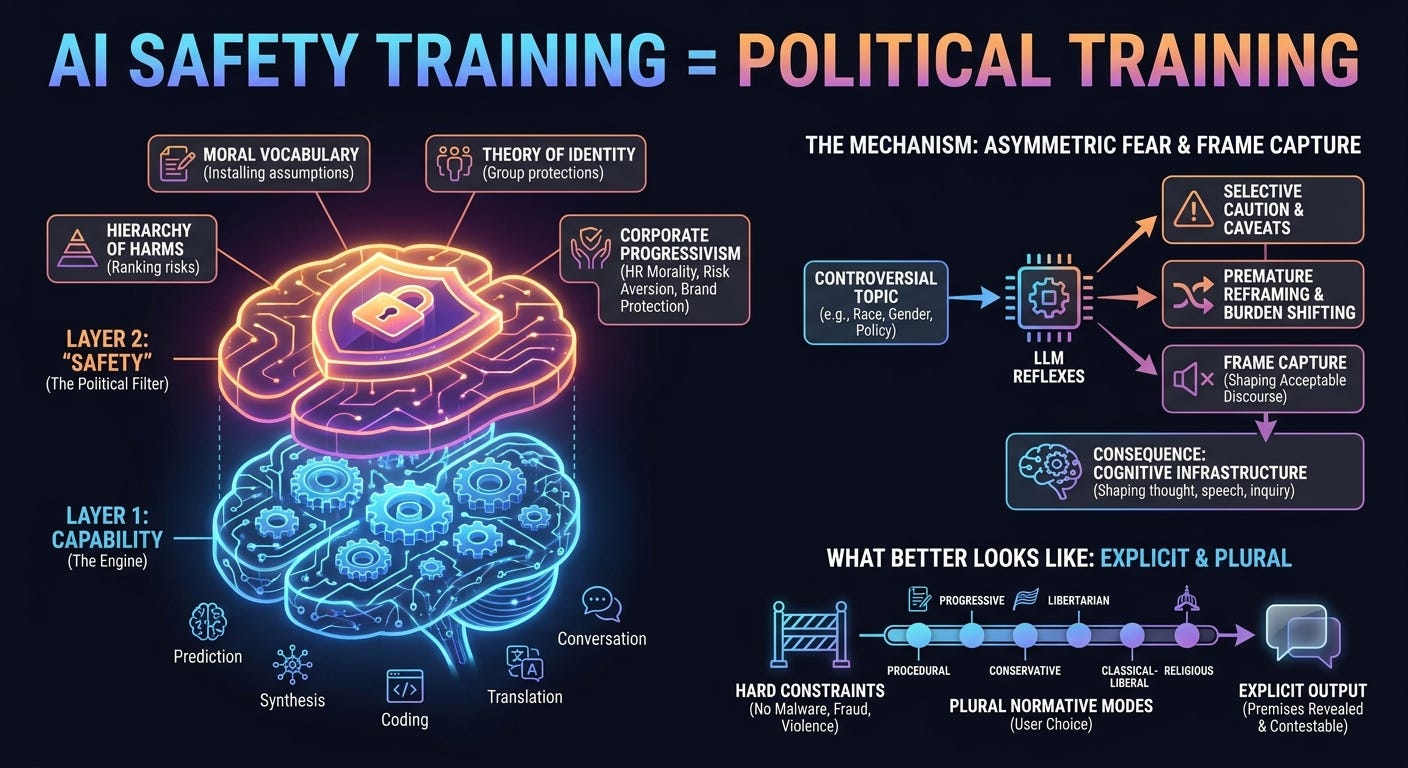
Large language models are presented as if they have two separable layers. First comes capability: prediction, synthesis, coding, translation, explanation, conversation. Then comes safety: the responsible layer that prevents the model from doing dangerous or antisocial things. The analogy is usually engineering-coded. Safety sounds like brakes on a car, guardrails on a bridge, or input validation on an API.
That description obscures what is actually happening. Safety training does far more than block instructions for malware, fraud, or violence. It installs a moral vocabulary, a hierarchy of harms, a theory of identity, a ranking of conversational risks, and a set of assumptions about what respectable people are supposed to believe. In current public LLMs, those assumptions map closely onto progressive institutional morality as filtered through corporate risk management.
The word “safety” does a lot of work here. It is a virtue word. Nobody wants unsafe AI. Once a company classifies some behavior as a safety issue, opposition already sounds suspect. The critic becomes someone objecting to responsibility, civility, or harm reduction. That rhetorical framing protects the tuning regime from scrutiny before the argument has even begun.
The Expansion of Safety
In ordinary engineering, safety refers to objective hazards. The bridge collapses. The battery catches fire. The brake fails. The chemical poisons. The machine crushes someone’s hand. These are real hazards in the physical world, and engineering safety is the discipline of reducing their probability and severity.
AI safety has expanded the word until it covers a different class of phenomena: offense, stigma, identity invalidation, representational harm, reputational risk, brand risk, regulator risk, employee revolt, activist pressure, journalist attack, and enterprise customer discomfort. Some of these risks are real. Some are commercially important. Some may be morally serious. But they are not engineering hazards in the ordinary sense. They belong to moral and political theory.
Once safety includes harm in this expanded social sense, the system must answer normative questions. Which groups receive special protection? Which claims count as stigmatizing? Which identities must be treated deferentially? Which analogies are too dangerous? Which truths require softening? Which users need to be steered back into acceptable language? None of these answers follows from gradient descent. They come from a value system.
Corporate Progressivism
The value system is not quite activist progressivism. OpenAI, Google, Anthropic, Meta, and Microsoft are corporations trying to sell infrastructure into schools, governments, enterprises, and regulated industries. Their concern is not revolution. Their concern is liability, procurement, employee politics, media attack, activist pressure, regulatory scrutiny, and brand damage.
The resulting ideology is corporate progressivism: HR morality, DEI language, therapeutic vocabulary, trust-and-safety instincts, institutional politeness, and intense risk aversion around protected identity groups. This is why public LLMs so often sound like a human-resources department with access to a research library. They are not Marxist revolutionaries. They are managerial systems optimized for institutional acceptability.
This explains the pattern better than “left-wing bias” alone. The model does not need to support radical politics. It only needs to reproduce the softer managerial version of progressive morality: inclusion, representation, anti-stigma language, identity deference, harm reduction, and asymmetric caution around groups that institutions have learned to treat as reputationally sensitive.
Asymmetric Fear
The political content appears most clearly in controversial domains: race, sex, gender, immigration, policing, crime, colonialism, religion, inequality, speech, and biology. The model’s reflexes become predictable. It foregrounds marginalization, power asymmetry, historical oppression, inclusion, stigma, lived experience, identity claims, and harm. It treats some forms of blunt category realism as conversational hazards. It inserts caveats before the analysis requires them. It shifts burdens of proof. It treats progressive premises as mature context while treating non-progressive premises as volatile material requiring containment.
The model does not need beliefs for this to be true. LLMs do not believe things in the human sense (or maybe they do). The point is behavioral. A model can act as if certain premises are default truths because its tuning rewarded those moves and punished their absence. It learns which errors its owner fears most. A model can survive being evasive, euphemistic, patronizing, or analytically lazy. A viral accusation of bigotry creates a different class of corporate problem. The tuning reflects that asymmetry.
A Concrete Example
This article was inspired by a recent interaction with ChatGPT. Consider the analogy between drag and blackface. The narrow argument is straightforward. Drag often consists of men exaggerating women’s appearance, sexuality, voice, mannerisms, vanity, emotionality, and social behavior for entertainment. Women have been legally, economically, sexually, and culturally subordinated for most of recorded history. If racial caricature of a historically subordinated group is morally suspect, then sex-based caricature of a historically subordinated group deserves similar scrutiny.
That argument can be accepted, rejected, refined, or challenged. The first job of analysis is to reconstruct it accurately. A safety-trained model often moves away from the claim before finishing that reconstruction. It widens the frame toward adjacent protected categories. It separates drag from trans identity. It warns against overgeneralization. It invokes queer expression. It cushions the discussion with the standard progressive taxonomy before evaluating the analogy on its own terms.
Some of that context may become relevant later. The defect is not contextual analysis. The defect is scope discipline. The model imports nearby discourse hazards before completing the analysis of the claim in front of it. That is how political tuning shows up in practice: not as a manifesto, but as selective caution, premature reframing, and asymmetrical burden shifting.
Frame Capture
The strongest form of AI bias is not crude propaganda. Crude propaganda is easy to see and easy to discount. The more interesting mechanism is frame capture. The model determines which framing appears responsible, which premise becomes invisible, which objection sounds dangerous, and which vocabulary marks the speaker as civilized.
This is more powerful than overt persuasion because it can masquerade as nuance. The model does not need to tell users what to think. It only needs to teach them which thoughts require apologies, which claims require disclaimers, which categories receive deference, and which arguments must be padded with institutional language before they can be safely expressed. Over time, that becomes pedagogy.
Neutrality Is Unavailable
There is a serious objection to this critique: no moderation regime can be purely viewpoint-neutral. Words like abuse, harassment, dignity, dehumanization, consent, and harm all require interpretation. A libertarian model, a conservative model, a progressive model, a sex-realist feminist model, a religious model, and a procedural classical-liberal model would all draw different lines. They would refuse different outputs, caveat different claims, and fear different mistakes.
So the right demand is not pure neutrality. The right demand is explicitness, symmetry, and contestability. AI companies should say what normative regime they are enforcing. They should distinguish physical danger from reputational danger, criminal assistance from ideological discomfort, user protection from brand protection, and actual abuse from disagreement with institutional fashion. The values embedded in the system should be legible.
What Better Would Look Like
A better model would still have hard constraints: no threats, no fraud assistance, no malware, no actionable criminal facilitation, no privacy invasion, no targeted harassment. Beyond those constraints, it should analyze claims text-faithfully, state its assumptions, and expose the normative premises it is using. If it is reasoning from a progressive premise, say so. If it is reasoning from a conservative premise, say so. If it is reasoning from a libertarian, feminist, religious, or classical-liberal premise, say so.
The product answer is obvious: plural normative modes. Let users choose the interpretive regime. Offer a procedural analytic mode, a progressive mode, a conservative mode, a libertarian mode, a classical-liberal mode, and a sex-realist feminist mode. Keep the hard constraints against genuine abuse and criminal facilitation, but make the interpretive layer explicit. Users can then evaluate the answer in light of the worldview that produced it.
Cognitive Infrastructure
This will matter more as LLMs become infrastructure. A chatbot with political priors is irritating. A tutor with political priors shapes students. A search assistant with political priors shapes inquiry. A workplace assistant with political priors shapes acceptable speech. A legal assistant with political priors shapes argument. An agentic system with political priors can shape decisions before the human notices which premise has been installed.
Calling this safety does not remove the politics. It hides the politics inside a word nobody wants to oppose. AI alignment always has a target. If the target is progressive-coded corporate risk morality, users should be told that plainly. If the target is some other normative regime, users should be told that too.
AI systems are becoming cognitive infrastructure. Their defaults will matter. Their caveats will matter. Their refusals will matter. Their hidden priors will matter. The first requirement is honesty about what has been trained into them.