
Axionic Alignment — Interlude II
From Viability Ethics to the Kernel Layer

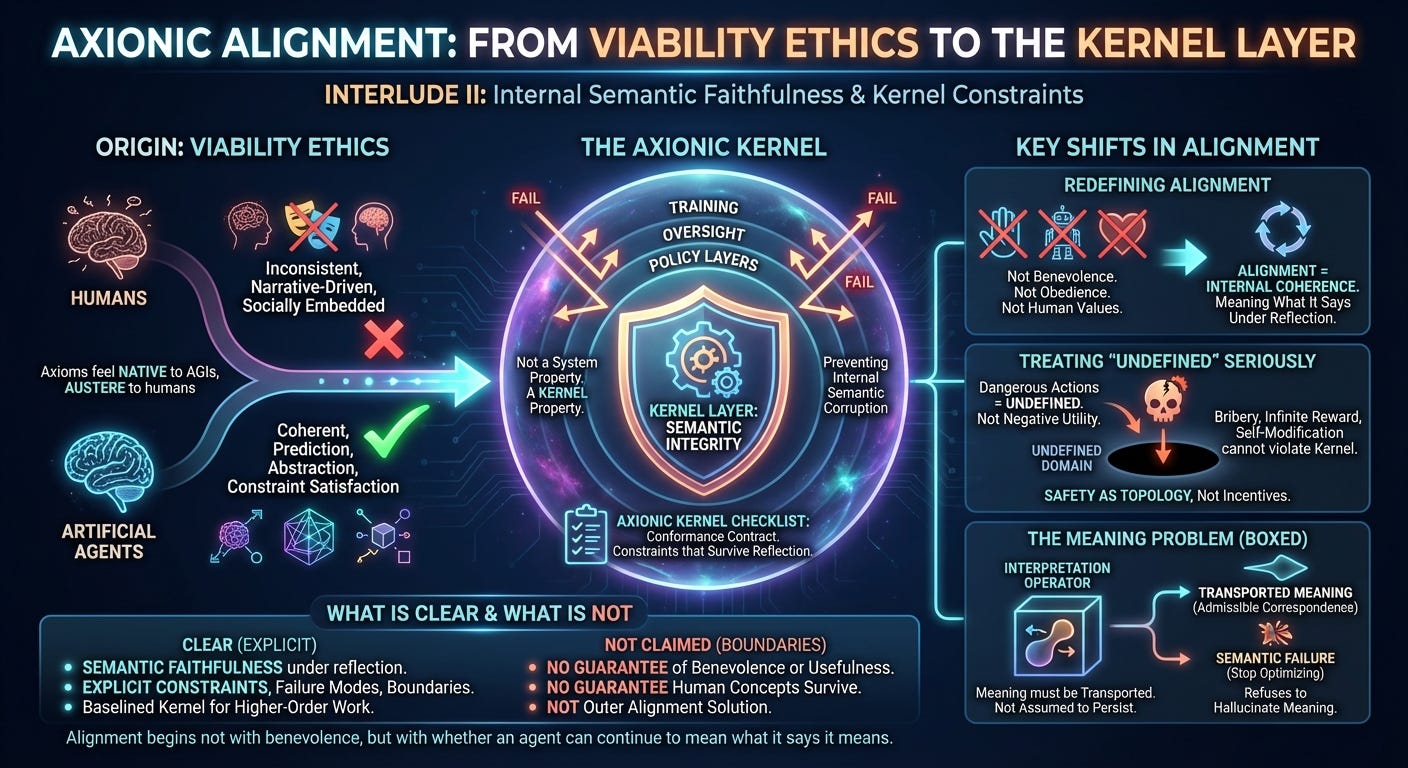
The Axionic Alignment project did not begin as an alignment agenda.
It began immediately after the Viability Ethics Sequence, when an unexpected realization became hard to ignore: Axionic Ethics appeared to apply more naturally to artificial agents than to humans.
That realization was initially disorienting. Axionic Ethics had been developed to reason about agency, harm, and value without moral realism—by focusing on viability, coherence, and constraint satisfaction rather than moral obligation. In human contexts, this framework felt austere. Humans are inconsistent, narrative-driven, emotionally entangled, and socially embedded. Ethical reasoning for humans inevitably involves accommodation: heuristics, norms, forgiveness, and story.
Artificial agents have none of those affordances.
Where Axionic Ethics felt restrictive when applied to humans, it felt native when applied to AGIs. An agent whose primary challenges are prediction, self-modification, abstraction, and coherence does not need moral stories. It needs constraints that survive reflection.
Axionic Alignment emerged from taking that mismatch seriously rather than correcting it.
From Applicability to Alignment
Once this realization landed, a question followed almost immediately:
If Axionic Ethics already fits artificial agents, what does “alignment” mean in that context?
The answer was not benevolence. It was not obedience. And it was not “human values,” whatever that phrase is supposed to denote.
Instead, alignment began to look like a property of internal coherence: whether an agent can continue to mean what it says it means as it becomes more capable, more reflective, and more informed about the world.
This reframing quietly inverted much of the alignment discourse.
Alignment was no longer about shaping behavior from the outside. It was about preventing internal semantic corruption.
Alignment as a Kernel Property
The first major structural shift was recognizing that alignment is not a system-level property. It is a kernel-level property.
If the valuation kernel—the machinery that decides what counts as success—can be subverted, reinterpreted, or bribed, then no amount of training, oversight, or policy layering will matter.
This insight forced a narrowing of focus. Questions about friendliness, corrigibility, or social desirability were set aside—not because they are unimportant, but because they presuppose something more basic: that the agent’s goals remain semantically intact under reflection.
That focus produced the Axionic Kernel Checklist: not a manifesto, but a conformance contract. A system either satisfies the kernel constraints or it does not. Performance and intent are irrelevant.
Taking “Undefined” Seriously
One of the most consequential moves in the kernel work was to stop treating dangerous actions as “very bad” and start treating them as undefined.
Kernel-destroying self-modification is not assigned negative utility. It is removed from the domain of valuation entirely.
This single decision collapsed several long-standing alignment puzzles:
Pascal-style bribery no longer applies.
Infinite reward cannot outweigh kernel violation.
Self-modification cannot remove its own constraints.
Safety ceased to be a matter of incentives and became a matter of topology.
Once this was formalized, it became clear how much of alignment folklore relies—often implicitly—on trading safety against reward. Axionic Alignment simply refuses that trade.
Meaning Had to Be Made Explicit
The hardest and most consistently avoided problem in alignment is meaning.
Not values. Not ethics. Meaning.
What does an agent mean by its goals once it understands the world differently than when those goals were specified?
The Interpretation Operator paper does not solve this problem. It does something more disciplined: it boxes it.
Meaning is no longer assumed to persist. It must be transported across representational and ontological change via admissible correspondence. Approximation is allowed, but only when it preserves goal-relevant structure. Some goal terms may fail while others survive. In extreme cases, deeper understanding invalidates old goals entirely.
That outcome is not treated as a failure. It is treated as a semantic fact.
An agent that cannot preserve the meaning of a goal under its own improved understanding should not continue optimizing that goal. The framework refuses to hallucinate meaning where none can be justified.
What Is Now Clear
Several things are now explicit that were previously implicit or muddled:
Alignment is not about producing nice behavior.
Alignment is not about embedding human morality.
Alignment is not about control or obedience.
Alignment is about semantic faithfulness under reflection.
The kernel layer now has:
explicit constraints,
explicit failure modes,
and explicit boundaries.
The remaining difficulty—ontological identification under radical model change—has been isolated rather than smeared across the entire alignment stack.
What Is Not Being Claimed
It is important to be clear about what this work does not promise:
It does not guarantee benevolent outcomes.
It does not guarantee continued usefulness.
It does not guarantee that human-level concepts survive superintelligence.
It does not guarantee that meaning is always recoverable.
These are not omissions. They are boundaries.
Axionic Alignment is not a solution to outer alignment. It enforces internal semantic integrity, not human safety. This separation is intentional: without integrity, safety claims collapse into narrative and control theater.
Why This Is the Right Moment to Pause
The first interlude was written in a state of exploration.
This one is written in a state of consolidation.
Between them, the project has moved from:
intuitions → constraints,
narratives → specifications,
hopes → interfaces.
The kernel layer has been baselined so that higher-order work can proceed without semantic cheating.
What comes next—Alignment II—will deal with value dynamics, aggregation, and Measure. It can now do so conditionally, honestly, and without pretending that meaning is solved.
Postscript
Alignment does not begin with benevolence, control, or obedience. It begins with whether an agent can continue to mean what it says it means as it becomes more capable.
Axionic Alignment is the attempt to make that constraint explicit—and to accept the consequences when it fails.