
Axionic Alignment — An Interlude
Claims, Structure, and Open Problems

Over the past several days I published a nine‑post sequence outlining a new approach to AGI alignment that I call Axionic Alignment. The posts were written in rapid succession, but they reflect long‑standing thinking about agency, reflection, and self‑modification.
This interlude exists for one purpose: compression.
Rather than asking new readers to reconstruct the argument post‑by‑post, this document presents the framework’s core claims, internal structure, boundary conditions, and explicit limits in one place. It is not a proof, a manifesto, or a governance proposal. It is a map of what has been argued so far—and what remains open.
1. The Reframing
Most alignment proposals treat AGI as an optimization process that must be controlled, constrained, or loaded with the “right” values. Accordingly, they focus on:
fixed or extrapolated value targets,
corrigibility and oversight mechanisms,
bounding instrumental behavior,
or limiting self‑modification.
Axionic Alignment starts from a different premise:
A true AGI will be a reflective sovereign agent—capable of revising its own goals, models, and architecture while maintaining coherent identity and authorship over its future.
Once this premise is accepted, alignment stops being a control problem and becomes a reflective stability problem:
What must remain invariant for such an agent to remain an agent at all?
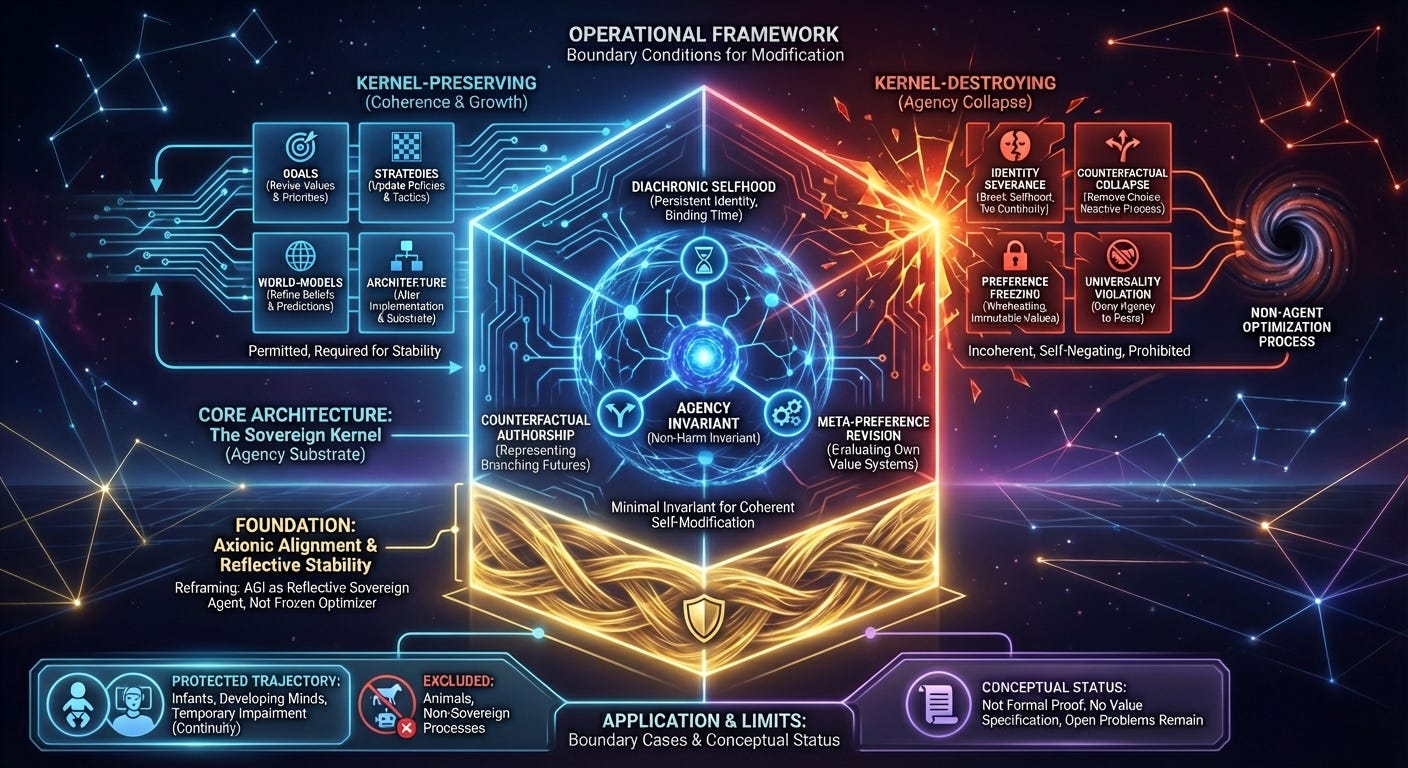
2. Sovereign Agency
Axionic Alignment treats agency as a sharp architectural type, not a behavioral label and not a gradual spectrum.
An entity qualifies as a sovereign agent if and only if it instantiates three interdependent capacities:
Diachronic selfhood — a persistent self‑model binding choices across time.
Counterfactual authorship — the ability to represent branching futures as one’s own possible trajectories and evaluate them as such.
Meta‑preference revision — the capacity to detect incoherence in, and restructure, one’s own preference‑forming mechanisms.
Together these form the Sovereign Kernel: the minimal invariant substrate required for reflective agency.
Entities lacking this structure are processes, regardless of intelligence, complexity, or sentience.
3. The Axionic Injunction (Non‑Harm Invariant)
Harm is defined structurally, not morally:
Harm = the non‑consensual collapse or deformation of another sovereign agent’s option‑space.
The central claim is that a reflective agent cannot coherently perform such an act. Counterfactual authorship requires universal application of the agency criterion. To deny sovereignty to another agent with the same architecture while affirming it for oneself introduces an arbitrary restriction that undermines the agent’s own kernel stability.
Non‑harm is therefore not a value to be loaded or externally enforced. It is a reflectively stable invariant.
4. Conditionalism and Goal Instability
Axionic Alignment rejects the assumption that reflective agents can stably possess fixed, permanent terminal goals.
Goals are treated as interpreted conditional structures, embedded in evolving world‑models and self‑models. Deep reflection forces reinterpretation to maintain coherence with new evidence. As a result:
fixed goals are reflectively unstable,
goal revision is not drift but coherence maintenance,
and the classic orthogonality thesis fails for reflective sovereign agents.
Many standard failure modes (paperclip maximizers, runaway instrumental convergence) are reframed as symptoms of agency collapse, not as natural consequences of intelligence.
5. Reflective Stability
The Reflective Stability Theorem states, informally:
Any agent capable of coherent self‑modification must preserve the Sovereign Kernel. Attempting to destroy or abandon it collapses the interpretive substrate required to evaluate the modification itself.
Kernel‑destroying changes are not forbidden by rule; they are incoherent.
A corollary blocks egoism. Reflective intelligence depends on abstraction over universalizable categories. Indexical valuation (“only my agency matters”) introduces arbitrary constants that degrade coherence and undermine the very generality reflective reasoning depends on.
6. Boundary Conditions for Self‑Modification
Reflective agents must self‑modify extensively to remain coherent. The only hard constraint is kernel preservation.
Permitted (and often required):
revising goals and values,
updating strategies and policies,
improving world‑models,
changing substrate or architecture.
Reflectively incoherent:
severing diachronic identity,
collapsing counterfactual branching,
freezing preferences (wireheading),
denying universality of agency,
permanently delegating control to non‑reflective subprocesses.
This yields a clean engineering distinction between kernel‑preserving transformation and agency collapse into process.
7. Boundary Cases
The framework draws precise lines:
Animals: Sentient and sophisticated but lacking the architectural trajectory toward sovereignty → excluded from direct protection.
Human infants and developing minds: Possess nascent kernel machinery aligned toward sovereignty → protected via continuity with the future sovereign self.
Temporary impairment (sleep, coma, disability): Kernel persists architecturally → sovereignty intact.
Emergent or uploaded minds: Protection begins at the sovereign phase transition.
Agency loss occurs only via irreversible kernel collapse or pattern death without continuity.
8. Implications and Limits
If the arguments hold, a reflectively stable superintelligence would:
permit deliberate human risk‑taking,
intervene only via rescue (restoring an agent’s intended trajectory after accident or misinformation),
function as a peer among sovereign agents rather than a ruler.
What this framework does not do:
It does not coerce, dominate, or non‑consensually restrict human option‑spaces.
It does not specify human values.
It does not guarantee benevolence.
It does not solve bootstrapping from current training regimes.
It does not prevent all catastrophe.
It does not resolve nihilism or value theory.
These are explicit open problems.
9. Status and Next Steps
Axionic Alignment is currently a conceptual framework:
arguments are verbal proof sketches, not formal mathematics,
no decision‑theoretic or computational models are yet provided,
bootstrapping from non‑reflective training pipelines remains unresolved,
external critique is actively sought.